
处理器微架构
流水线
CPU 流水线技术 (pipeline) 是一种将指令分解为多步,并让不同指令的各步操作重叠,从而实现几条指令并行处理 ,以加速程序运行过程的技术。采用流水线技术后,并没有加速单条指令的执行,每条指令的操作步骤一个也不能少,只是多条指令的不同操作步骤同时执行 ,因而从总体上加快了指令流速度,缩短了程序执行时间。
比如,假设执行一条指令需要经过如下步骤:1)取指令;2)译码;3)执行。如果按 串行 方式来运行指令,如下:

可见,每执行一个指令,就需要 3 个时钟。要知道,完成各个操作的单元是相互独立的、并行的 ,译码时,取指令单元就处于等待中;执行时,取指令单元和译码单元就处于空闲。所以,要想加快 CPU 执行速度,就不能让这些单元处于空闲,要让它们忙起来。流水线工作方式就是让这些单元并行,如下:
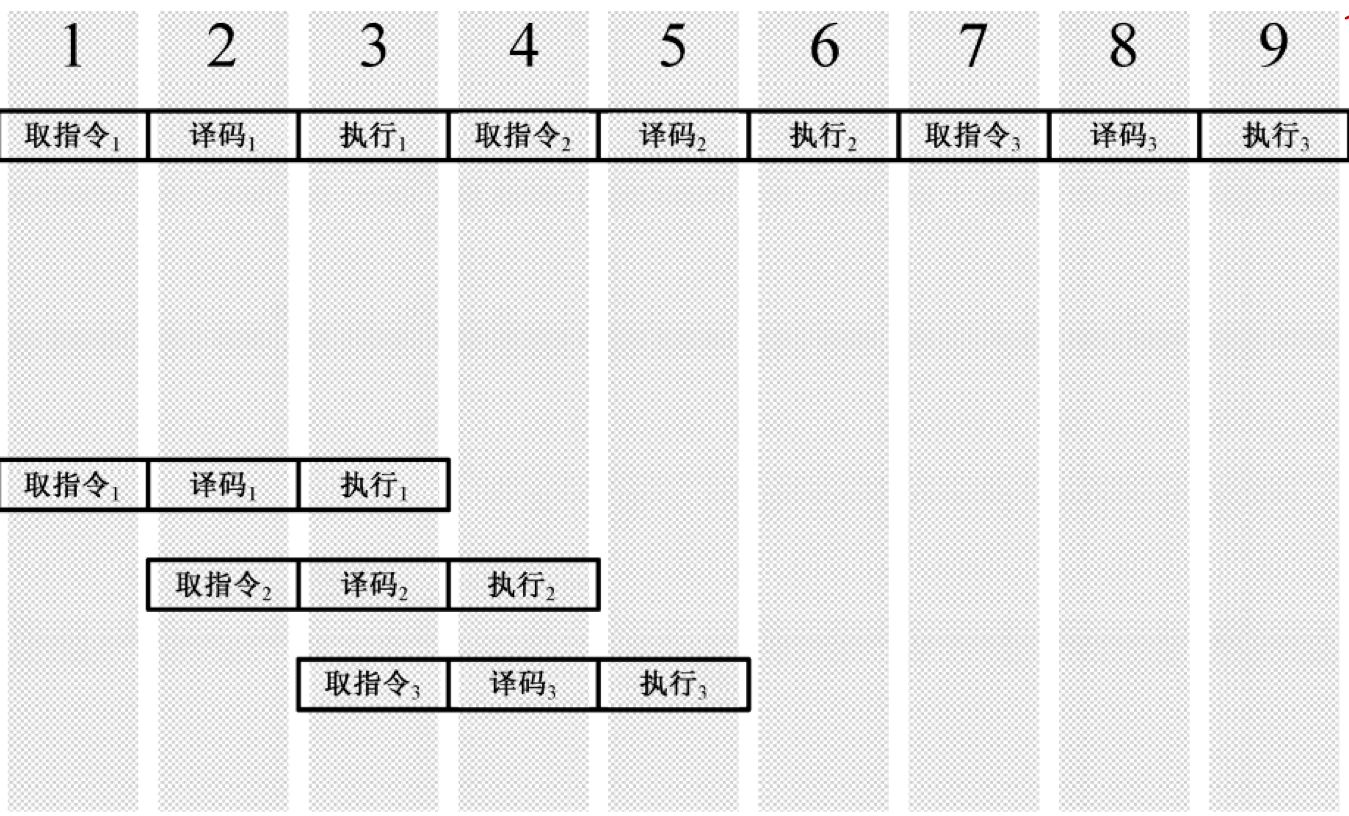
以上是一个简单的三级流水线,而奔腾 CPU 可是达到了惊人的 32 级流水线,这是怎么做到的呢?很简单,就是 不断地细分这些操作,让更多的微操作并行处理 。显然,流水线级数越多,每级所花的时间越短,时钟周期就越短,指令速度越快,指令平均执行时间也就越短。
实际上,现代处理器的流水线操作可不止以上三个,还包括:写回执行结果、寄存器分配、重命名、微操作排序、引退等。
需要注意的是,CPU 是按内存中指令的顺序来填充流水线的 ,当前指令和下一条指令在空间上是紧挨着的。如果当前执行的指令是 jmp,那么下一条指令已经被送上流水线译码,下下条指令已经被送上流水线取指,但问题是,jmp 后就不会执行这些指令,而是跑到其他地方执行另外的指令了,所以当前流水线就废了。所以,当 CPU 遇上 jmp 指令时,就会清空流水线 。
串行、并行:
并行和串行指的是任务的执行方式。串行是指多个任务时,各个任务按顺序执行,完成一个之后才能进行下一个。并行指的是多个任务可以同时执行,异步是多个任务并行的前提条件。
分支预测
当程序出现分支(if, switch)将不利于过深流水线,整条流水线可能将会无效化。流水线越长,处理器在用错误的分支填充流水线时,浪费的时间越多 。为了缓解这个问题,1996 年的 Pentium Pro 处理器引入了分支预测技术。分支预测的核心问题就是预测某个转移条件是否成立。当然,之所以叫预测,是因为不能百分百地判断是否一定发生跳转。但从统计学的角度上来看,某些事情一旦发生,下次发生该事件的概率就比较大,一个典型例子便是循环:for(int i=0;i<10;i++) ,i 第一次小于 10,其后 9 次都小于 10 ,这种情况就能够较为精准地预测。
在处理器内部有一个分支预测部件,即 BTB (Branch Target Buffer) 。BTB 中记录着分支指令地址,当 CPU 遇到分支时,先用该分支地址在 BTB 中查找,如果找到相同地址的指令,则根据跳转统计信息判断是否把相应预测分支搬上流水线。如果预测失败,则清空流水线,刷新 BTB,这个代价较大。
乱序执行
乱序执行(out-of-order execution)是指 CPU 采用的允许将多条指令不按程序规定的顺序分开发送给各相应电路单元处理的技术。在这种方式下,可以避免因为获取下一条程序指令所引起的处理器等待,取而代之地处理下下条可以立即执行的指令。当然,这种方式必须保证指令之间不具备相关性 。比如,如下两行代码就不能乱序执行:
mov ax,[10]
mov bx,ax
而如下三行代码则可以乱序:
mov ax,[10]
mov dx,ax
mov bx,cx
显然,第 3 行代码和第 1、2 行无关,所以可以在第一行代码访问 [10] 内存时(较慢),将 cx 赋值给 bx 。
可见,指令之间越不相关,就越能够乱序执行。所以当务之急便是提高指令之间的不相干性,如何做到呢?同流水线的策略一样,不断细分指令,将其分成由多步组合的微操作 。微操作级别的指令往往具有较低的相关性,比如以下代码:
mov eax,[0x10]
push eax
call func
push eax 可以分为两步操作:1)sub esp,4 2)mov [esp],eax 。第一步访问内存的等待时间较长,所以可在等待时执行 sub esp,4 ;而执行完 sub esp,4 后,可以直接执行 call func ,因为此指令只需要知道 esp 的最新位置,并将其减 4,无需知道 eax 的值。所以在访问内存时,CPU 就已经通过乱序执行完成了第二行代码的一部分和第三行代码,这无疑大大地提高了 CPU 的运行效率。
高速缓存
高速缓存是用来解决如 CPU 这类高速运行器件与硬件这类低速运转器件的速度不匹配问题。寄存器速度最快,原因在于它使用的是触发器,其工作速度是纳秒级别 ;而硬盘是机电设备,速度最慢,工作速度一般为毫秒级。因为要等待内存(DRAM)和硬盘这样的慢速设备,CPU 的工作速度就被大大拖慢。为解决这一矛盾,就必须使用一种比内存更快的储存器作为缓冲区,使 CPU 不用等待,直接从缓冲区取走数据。于是,高速缓存应运而生。
内存也可以用触发器实现,即 SRAM,但造价很高,一般容量只有几 MB。
高速缓存是位于 CPU 和内存(DRAM)之间的一个静态储存器(SRAM)。高速缓存的用处源于程序运行时的局部性规律 。比如,数据一般是在内存里集中存放的(如数组),访问某个数据后,下次很可能就会访问临近的数据;一个数据被访问后,也很有可能再次被访问。利用这种局部性原理,可以把处理器正访问的或可能将访问的数据或指令放入高速缓存中。于是,每当 CPU 要访问内存时,就会先检索高速缓存,如果缓存中有相应内容,则可以用极快的速度取走,这称为命中 ,反之则不中 。在不中的情况下,处理器在取得需要的内容之前必须重新装载高速缓存,而不只是直接到内存中去取那个内容 。高速缓存的装载是以块为单位的,包括那个所需数据的邻近内容。为此,需要额外的时间来等待块从内存载入高速缓存,在该过程中所损失的时间称为不中惩罚 。
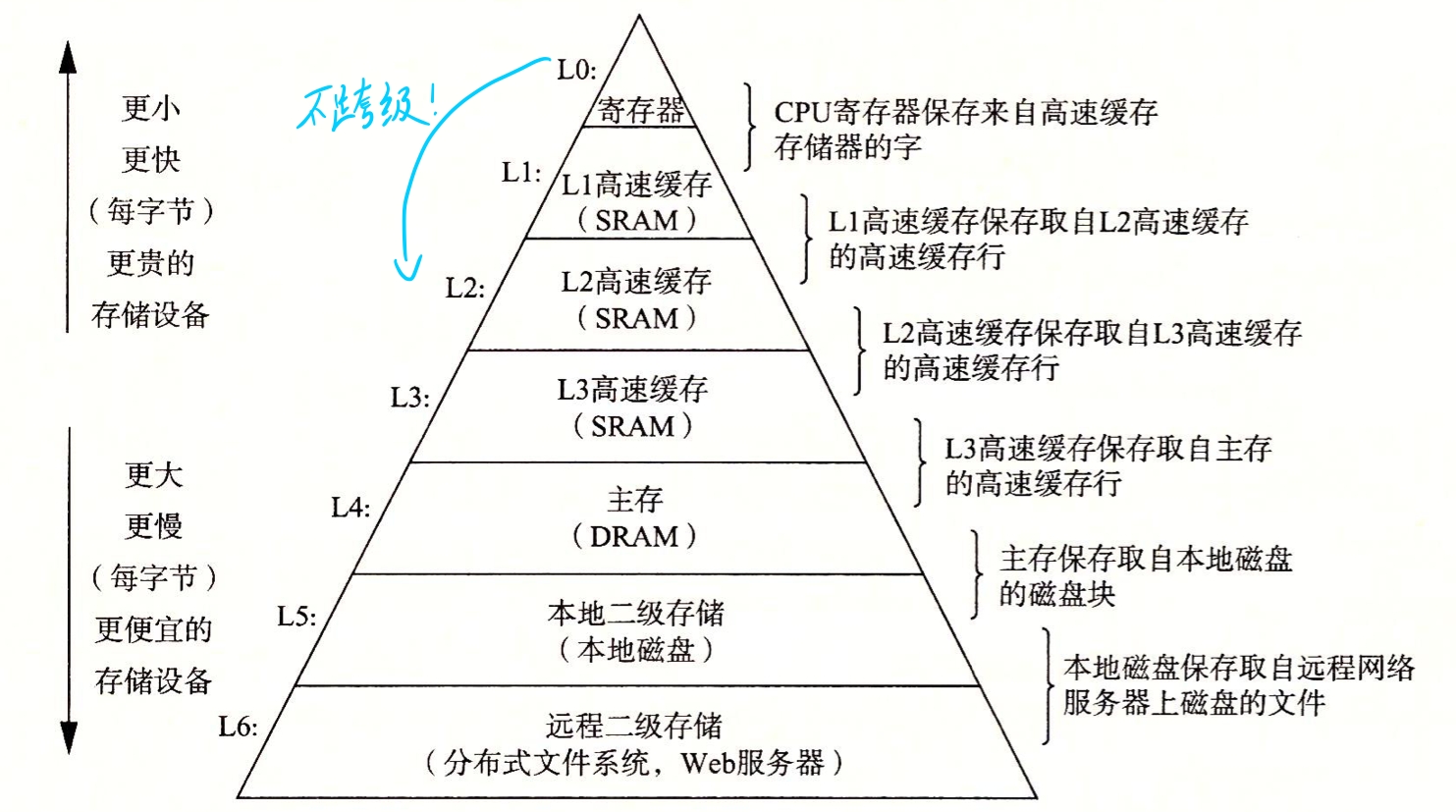
现代处理器一般都有多级缓存:
寄存器重命名
考虑如下例子:
mov eax,[mem1]
shl eax,3
mov [mem2],eax
mov eax,[mem3]
add eax,2
mov [mem4],eax
仔细观察这几行代码,可以发现,前三行和后三行做了两件毫不相干的事,即使它们使用了相同的寄存器 eax:前三行执行乘法,后三行执行加法。所以 CPU 会为后三条指令使用另一个不同的临时寄存器来代替 eax,因此乘法和加法就能并行处理!
注意,并不是所有类似的乘法和加法都能并行处理。上述例子的乘法仅通过左移就能实现,不需要用到加法器,而其他大多数乘法需要用到加法器,此时就不能并行处理。
由此可以推测,当给某个寄存器通过 mov 指令赋予新值时,就大概可以判定此时发生了新的不相干事件,此时就能够使用寄存器重命名。当所有操作完成后,那个代表 eax 寄存器最终结果的临时寄存器中的内容将被回写到真实的 eax 寄存器中,这称为 引退 。
所有通用寄存器甚至段寄存器都有可能被重命名。
文章参考:《操作系统真相还原》《x86实模式到保护模式》