
二叉树的序列化与反序列化
序列化是把对象转换成有序字节流,以便在网络上传输或者保存在本地文件中,其核心作用是对象状态的保存。
反序列化是从文件中或网络上获得序列化后的对象字节流,根据字节流中所保存的对象状态及描述信息在内存中重建对象。
本文用 C++ 代码简单描述二叉树的序列化和反序列化。
前序序列化
我们将二叉树序列化为字符串,规定:空节点用 # 表示,每条数据用 , 隔开。
序列化操作还是很简单的,只是在前序遍历时额外添加一些字符串操作,代码如下:
void serializePre_in(TreeNode* nd, string &str)
{
if(nd == nullptr)
{
str += "#,";//容易忽略
return;
}
str += to_string(nd->data);
str += ",";
serializePre_in(nd->left, str);
serializePre_in(nd->right, str);
}
string serializePre(TreeNode* root)
{
if(root == nullptr)
return "";
string str;
serializePre_in(root, str);
return str;
}
前序反序列化
前序反序列化的思路是:1)将前序序列化得到的字符串还原成原始、独立的整形数据,并压入队列;2)既然是前序序列化得到的结果,那么反序列化也应该用前序的方式去依次消费队列。代码如下:
#include<sstream> //stringstream
TreeNode* deserializePre_in(queue<string> &strQue)
{
string str = strQue.front();
strQue.pop(); //消费队列
if(str == "#")
return nullptr;
TreeNode* nd = new TreeNode(stoi(str));
nd->left = deserializePre_in(strQue);
nd->right = deserializePre_in(strQue);
return nd;
}
TreeNode* deserializePre(string str)
{
if(str.empty())
return nullptr;
TreeNode* root;
string token;
queue<string> strQue;
stringstream ss(str); //这里容易忽略初始化
while(getline(ss, token, ',')) //‘,’作为界定符,每次划分得到的字符串赋值给token
strQue.push(token);
root = deserializePre_in(strQue);
return root;
}
思路很清晰,需要注意是第 21~23 的字符串处理,这里是在以 , 为界定符分割字符串。
后序序列化
后序序列化和前序序列化无异,仅仅变动了添加字符串动作的位置,代码如下:
void serializePost_in(TreeNode* nd, string &str)
{
if(nd == nullptr)
{
str += "#,";
return;
}
serializePost_in(nd->left, str);
serializePost_in(nd->right, str);
str += to_string(nd->data);
str += ",";
}
string serializePost(TreeNode* root)
{
if(root == nullptr)
return "";
string str;
serializePost_in(root, str);
return str;
}
后序反序列化
后序反序列化就需要迂回了。你可不能直接将创建节点的动作放在进入左右子树动作的后面,连父节点都没有,何谈直接进入子节点呢?
在 二叉树的非递归遍历 一文中,非递归后序遍历综合了以下三种顺序:
头结点 -> 左孩子 -> 右孩子 (序1
头结点 -> 右孩子 -> 左孩子 (序2
左孩子 -> 右孩子 -> 头结点 (序3
其中序 1 即前序,序 3 即后序。换句话说,后序遍历可以这样得到:先访问头结点,再访问右孩子,然后访问左孩子,最后将访问结果反序。文字可能不直观,还是用图来表达吧,如下:
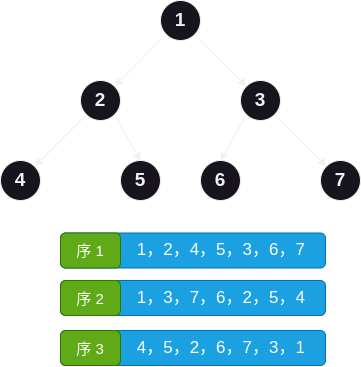
那么这种关系能用于反序列化吗?当然,我们只需要将后序序列化结果进行反序处理(变成序 2),然后在创建节点后先进入右孩子,再进入左孩子即可。代码如下:
TreeNode* deserializePost_in(stack<string> &stk)
{
string str = stk.top();
stk.pop();
if(str == "#")
return nullptr;
TreeNode* nd = new TreeNode(stoi(str));
nd->right = deserializePost_in(stk); //注意先进右
nd->left = deserializePost_in(stk); //再进左
return nd;
}
TreeNode* deserializePost(string str)
{
if(str.empty())
return nullptr;
TreeNode* root;
string token;
stringstream ss(str);
stack<string> stk;
while(getline(ss, token, ','))
stk.push(token);
root = deserializePost_in(stk);
return root;
}
这里我们用栈而非队列来存放处理好的字符串,可以很自然地完成反序步骤。
层序序列化
层序序列化和反序列化都是几乎直接在层序遍历代码上稍作修改,清晰易懂。
string serializeLayer(TreeNode* root)
{
if(root == nullptr)
return "";
string str;
TreeNode* tmp;
queue<TreeNode*> que;
que.push(root);
while(!que.empty())
{
tmp = que.front();
que.pop();
if(tmp == nullptr)/**易忽略**/
{
str.append("#,");
continue;
}
str.append(to_string(tmp->data)).append(",");
que.push(tmp->left);
que.push(tmp->right);
}
return str;
}
层序反序列化
TreeNode* generatenode(queue<string> &que)
{
string tmp = que.front();
que.pop();
if(tmp != "#")
{
TreeNode* nd = new TreeNode(stoi(tmp));
return nd;
}
else
return nullptr;
}
TreeNode* deserializeLayer(const string &str)
{
if(str.empty())
return nullptr;
queue<string> que_str;
queue<TreeNode*> que_node;
stringstream ss(str);
string token;
while(getline(ss, token, ','))
que_str.push(token);
TreeNode *tmp, *root;
root = generatenode(que_str);
if(root == nullptr)
return nullptr;
que_node.push(root);
while(!que_str.empty())
{
tmp = que_node.front();
que_node.pop();
tmp->left = generatenode(que_str);
tmp->right = generatenode(que_str);
if(tmp->left != nullptr) // 只放非nullptr节点;
que_node.push(tmp->left);
if(tmp->right != nullptr)
que_node.push(tmp->right);
}
return root;
}
那么,为什么没有中序序列化和反序列化呢?因为序列化和反序列化是唯一对应的,前者能唯一导出后者,后者能唯一导出前者。而中序存在歧义,不同的两棵树可能存在相同的中序序列化结果,如下图:
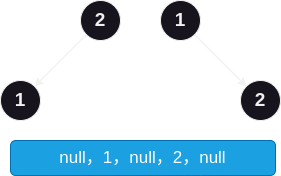
因此我们无法使用中序来完成序列化和反序列化。
文章参考:什么是序列化和反序列化 ,左程云算法课