
动态规划-最长公共子序列(三种解法)
问题描述
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在公共子序列,返回 0 。
- 子序列:由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。例如,
"ace"是"abcde"的子序列,但"aec"不是"abcde"的子序列。- 子串:原字符串的某一连续部分。例如,
"abc"是"abcde"的子串,但"ace"不是"abcde"的子串。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
本文章将使用三种方法解决此题,前两种是本人头脑风暴想出来的暴力解法,速度并未达标但思路非常漂亮;第三种是标准的动态规划解法。
解法一
我拿到此题后的第一感觉是:既然给了我两个字符串,要求得它们的最长公共子序列,按生活习惯似乎应该取其中一个字符串作为标准参照,另一个字符串则由我们任意对比和操作。
语言不好描述,还是直接上图吧:
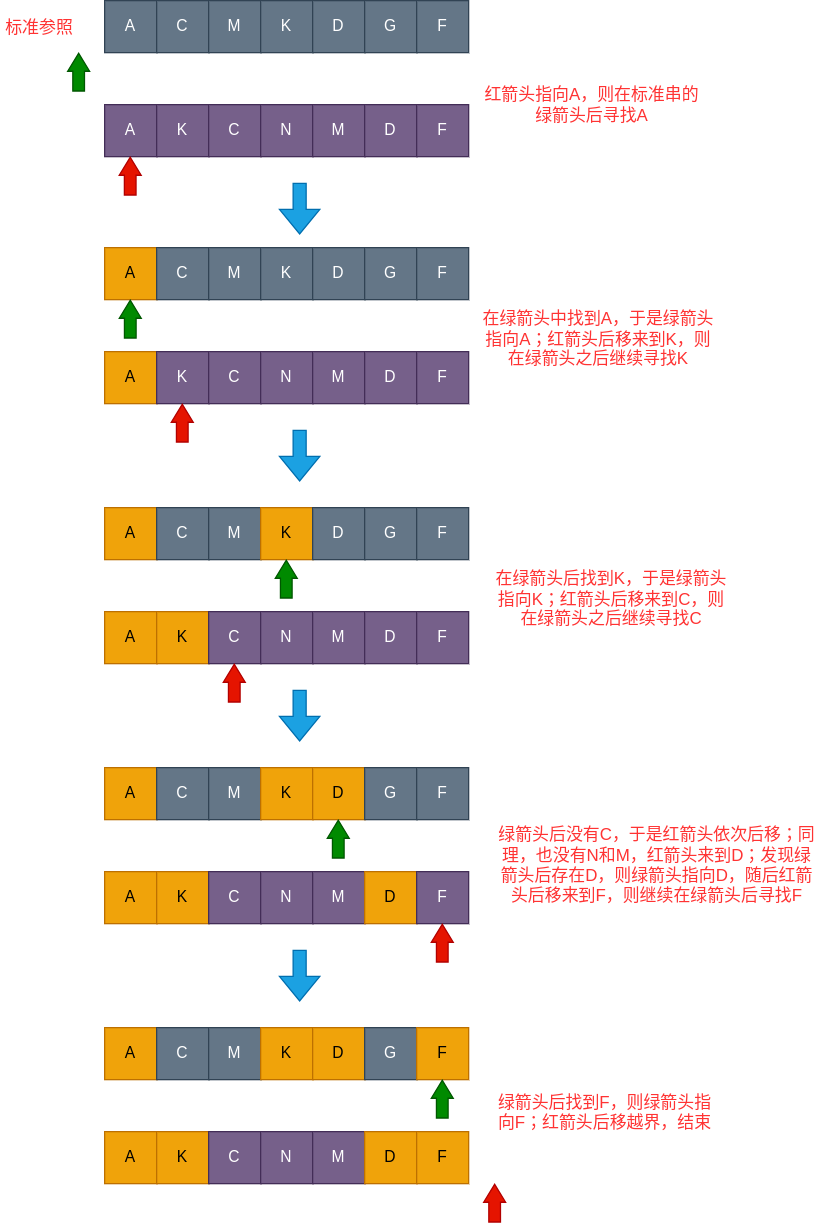
上图中灰色字符串即为标准参照串,紫色字符串为我们的操作字符串。以上是我们将操作字符串 AKCNMDF 视作整体时的过程,但我们很快就能发现,这两个字符串的最长公共子序列并不是图中得到的 AKDF ,而是 ACMDF 。那问题出在哪呢?其实也不难想到,这是因为我们将 K 算进了公共子序列, 由于算入了 K ,标准串中的 CM 就位于了绿色箭头之前,因此无法与操作字符串中后续的 CM 进行匹配 。那该怎么办?很简单,删掉操作字符串中的 K 即可,重复以上过程我们就可以得到最长公共子序列 ACMDF 。
通过上面的过程我们有所发现:如果标准串中存在一个匹配项,那么这个匹配项的位置越靠后,则得到的公共子序列越短 。如下图:
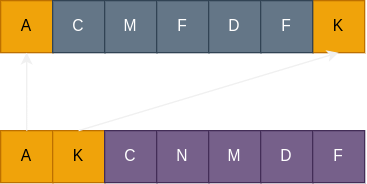
换句话说,每个匹配项都有可能阻碍我们寻找更长的公共子序列,所以必须尝试跳过该项不进行匹配,然后比较出所有情况下的最大值。
代码如下:
//str-标准字符串
//sub-操作字符串
int longestCommonSubsequence(const string &str, string sub)
{
if(sub.empty())
return 0;
vector<int> record;//记录匹配项在操作字符串中的位置
int preMark = -1;//绿色箭头
for(int i = 0; i < sub.length(); i++)//i为红色箭头
{
int pos = str.find(sub[i], preMark + 1);//preMark+1即从绿箭头之后开始查询
if(pos == std::string::npos)//如果没有匹配,则红色箭头后移
continue;
record.push_back(i);
preMark = pos;
}
int max = record.size();
for(auto p : record)
{
string copy = sub;//因为每次只删一个匹配项,所以不能直接在sub上删除
int ret = longestCommonSubsequence(str, copy.erase(p, 1));//删除该匹配项后继续尝试寻找公共子序列
max = max > ret ? max : ret;
}
return max;
}
显然,上述代码可以添加记忆化搜索,虽然效率有所提高,但还是无法通过力扣的时间要求。各位读者可以尝试用更高效的剪枝策略,如果有想法,还请在评论区提出。
解法二
两个字符串不同于其他题目中的两个整形状态变量,对于后者,我们可以建立一张二维表。那两个字符串能建表吗?我们似乎很难想出为字符串建表的意义。试试看也不碍事,建表如下:
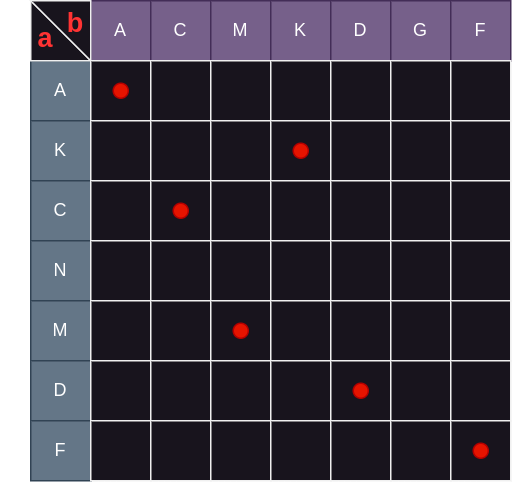
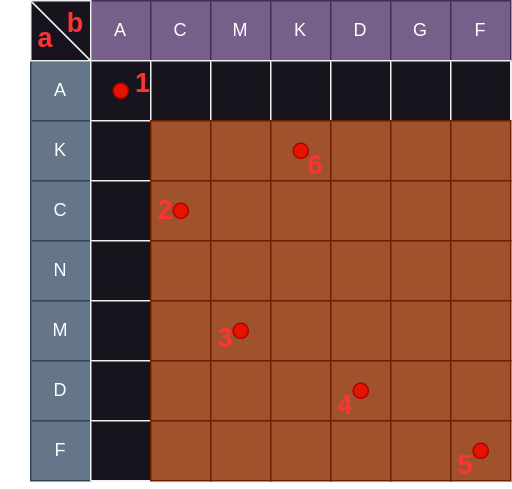
表的行和列分别是字符串 a 和字符串 b,两者公共的字母用红点标记。emm… 思索不久后有一个惊人的发现:最长公共子序列就是图中红点所连成的斜线的最大路径! 如下图,将各个红点编号:
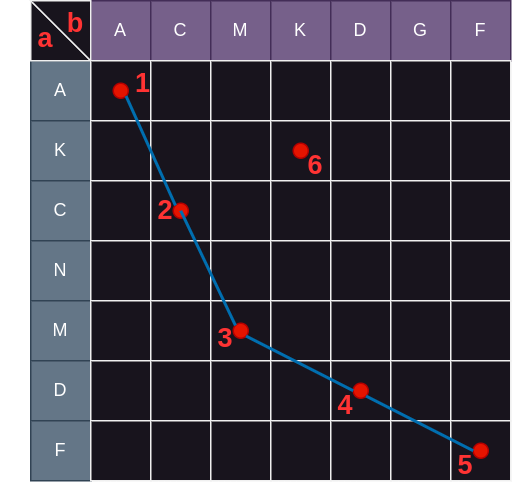
图中的斜线有很多种情况,比如:1->6->4->5,1->6->5,1->3->4->5,1->2->3>4,2->3->4 等等。但显然,其中最长的斜线为 1->2->3->4->5,对应的最长公共子序列为 ACMDF 。
注意这里斜线的定义:如果要从点 1 走向点 2 ,那么要求点 2 的行和列必须分别大于点 1 的行和列,不能等于!
这个道理只可意会,难以言传。
所以这道题就转变成了求散点的最长斜路径问题 。这也不难,递归代码如下:
int next(const vector<vector<bool>> &points, int row, int col)
{
if(row >= points.size() || col >= points[0].size())//边界处理
return 0;
int count;
int max = 0;
//在r>row且c>col的范围上寻找最长斜路径
for(int r = row; r < points.size(); r++)
{
for(int c = col; c < points[0].size(); c++)
{
if(points[r][c])
{
count = 1 + next(points, r + 1, c + 1);//+1是因为算上此点
max = max > count ? max : count;
}
}
}
return max;
}
int longestCommonSubsequence(string strA, string strB)
{
vector<vector<bool>> points(strA.size(), vector<bool>(strB.size(), false));
for(int a = 0; a < strA.length(); a++)
{
for(int b = 0; b < strB.length(); b++)
{
if(strA[a] == strB[b])
points[a][b] = true;//标记公共字符
}
}
return next(points, 0, 0);
}
上面的代码是什么意思呢?以上面的图为例,在第 13 行代码我们首先会取得点 1,然后调用 next 函数寻找后续的最长路径,由于是斜线(不能水平,也不能竖直),所以传入 next 的范围应该小于点 1(r,c),即应该传入 r + 1 和 c + 1(见下图) 。在每一层递归的 row 和 col 范围内,以每一个点为起始点开始计算路径长度,取最大值返回。
速度当然出奇的慢,是否能优化呢?显然在上述过程中一定会重复遍历同一个点,所以记忆化搜索能够派上用场。还能怎么优化?发现在当前递归中,完全不需要以范围内所有的点为起始点挨个尝试一遍,这很好理解:还是以之前的图为例,在第一层递归中首先取得点 1,然后调用 next 进入下一层递归;那么新递归的范围为 row > 1 且 col > 1:
既然点 1 的范围更大,包含的点更多,那为什么还要在同一层递归中去尝试其他的点?其他的点范围更小,包含的点更少,最后的结果也只可能更小。
因此,我们只需要尝试最外围的点即可。 问题在于,如何定义“外围”?这需要我们好生思考。考虑下面的情况:
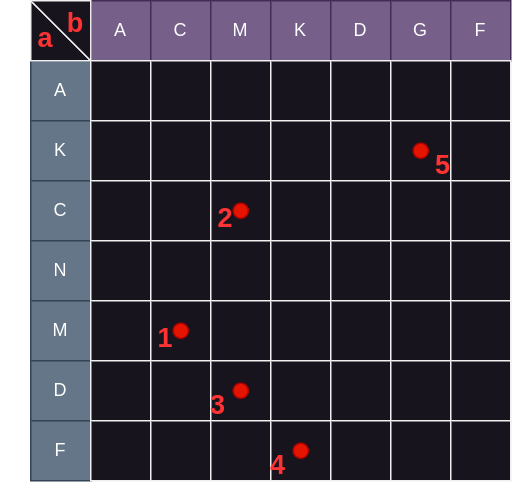
上图中点 1、2、5 即为外围点,为什么?因为 1 不能包含 2 和 5;2 不能包含 1、3、5;5 则不能包含任何点;而 3、4 能够完全被 1 围住,所以不是外围点。
确定外围点的代码如下:
int preCol = INT32_MAX;
for(int r = row; r < points.size(); r++)
{
for(int c = col; c < points[0].size(); c++)
{
if(c < preCol && points[r][c])
{
count = 1 + next1(points, r + 1, c + 1, memo);
max = max > count ? max : count;
preCol = c;
break;
}
}
}
上述代码的含义为:某一行中,列序号©最小的那个点可能为外围点,还需进一步判断:如果之前已经出现过外围点(其列序号为preCol),那么 c < preCol 时该点才是外围点,否则不是。仔细画图理解还是很好懂的,就不赘述啦。
最终优化后的代码如下:
int next(const vector<vector<bool>> &points, int row, int col, vector<vector<int>> &memo)
{
if(row >= points.size() || col >= points[0].size())
return 0;
if(memo[row][col] != 0)
return memo[row][col];
int count;
int max = 0;
int preCol = INT32_MAX;
for(int r = row; r < points.size(); r++)
{
for(int c = col; c < points[0].size(); c++)
{
if(c < preCol && points[r][c])
{
count = 1 + next(points, r + 1, c + 1, memo);
max = max > count ? max : count;
preCol = c;
break;
}
}
}
memo[row][col] = max;
return max;
}
int longestCommonSubsequence(string strA, string strB)
{
vector<vector<bool>> points(strA.size(), vector<bool>(strB.size(), false));
vector<vector<int>> memo(strA.size(), vector<int>(strB.size(), 0));
for(int a = 0; a < strA.length(); a++)
{
for(int b = 0; b < strB.length(); b++)
{
if(strA[a] == strB[b])
points[a][b] = true;
}
}
return next(points, 0, 0, memo);
}
优化后速度大幅提高,但在力扣提交代码时仍然会超出时间限制。其实只要加入了记忆化搜索,其复杂度就能够和动态规划相同,达到 O(M*N) ,只不过递归本身的时间开销以及函数内部的常数时间过大,所以无法通过测试 。
解法三
和之前的文章一样,要搞动态规划,还得先从暴力递归开始。既然现在的导向是动态规划,那么递归函数的参数必须设计成有利于动态规划的形式。有两个字符串,那咋们就不管三七二十一,先为每个字符串加上一个状态变量 :
int process(const string &strA, const string &strB, int indexA, int indexB);
可以猜测,该函数的功能为:返回 strA 的 0~indexA 范围上与 strB 的 0~indexB 范围上的最长公共子序列的长度。
现在我们再来想如何利用上面的递归函数来寻找最长公共子序列。既然递归函数如此设计,那我们的目光应该重点落在 indexA 和 indexB 对应的这两个位置,而两者之前的 0 ~ indexA - 1 和 0 ~ indexB - 1 范围则交给递归函数自身处理。
这两个位置该怎么处理呢?分为三种情况:
- 如果 strA[indexA] = strB[indexB] ,那么这对匹配项一定会算在最后的结果里 。
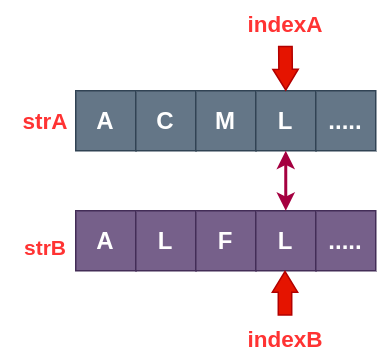
如果 strA[indexA] != strB[indexB],那我们就该直接进入 0 ~ indexA - 1 和 0 ~ indexB - 1 中继续处理吗?不能,还应该分为以下两种情况:
- indexA 对应的字符 可能 存在于 strB 的 0 ~ indexB - 1 范围上:
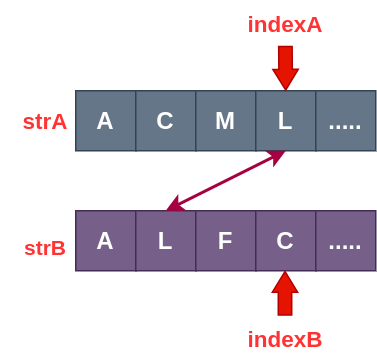
- indexB 对应的字符 可能 存在于 strA 的 0 ~ indexA - 1 范围上:
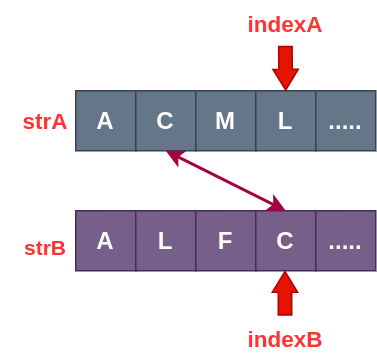
所以可得递归代码如下:
int process(const string &strA, const string &strB, int indexA, int indexB)
{
if(indexA < 0 || indexB < 0)
return 0;
if(strA[indexA] == strB[indexB])
return 1 + process1(strA, strB, indexA - 1, indexB - 1);
int case1 = process1(strA, strB, indexA - 1, indexB);
int case2 = process1(strA, strB, indexA, indexB - 1);
return std::max(case1, case2);
}
int longestCommonSubsequence(string strA, string strB)
{
return process(strA, strB, strA.length() - 1, strB.length() - 1);
}
我天!太简洁了吧…这很好改成动态规划,不解释直接上代码:
int longestCommonSubsequence(string strA, string strB)
{
vector<vector<int>> dp(strA.length(), vector<int>(strB.length(), 0));
for(int a = 0; a < strA.length(); a++)
{
for(int b = 0; b < strB.length(); b++)
{
if(strA[a] == strB[b])
{
dp[a][b] = 1 + ((a - 1 < 0 || b - 1 < 0) ? 0 : dp[a-1][b-1]);//注意边界处理
continue;
}
dp[a][b] = std::max(a - 1 < 0 ? 0 : dp[a-1][b], b - 1 < 0 ? 0 : dp[a][b-1]);//注意边界处理
}
}
return dp[strA.length()-1][strB.length()-1];
}
总结
-
本人受之前的动态规划题目-拼纸贴词影响,误以为暴力递归总可以通过记忆化和各种剪枝技巧来达到和动态规划(表依赖)一样的速度。一般而言,暴力递归加上记忆化搜索后,时间复杂度就已经同动态规划了,至于为什么还比动态规划慢这么多,推测有至少三点原因:
- 是因为递归本身的时间开销巨大。
- 函数内部常数时间消耗大。
- 没有剪枝,无效解多。
因此,最好不要再花过多时间去考虑将暴力递归剪枝优化成动态规划那样的速度,基本做不到!不过用来训练思维倒是挺不错的,就是太花时间了,呜呜呜。
-
解决本题的动态规划时,我们利用了一种逆向思路:既然知道本题可以用动态规划,那就先设计出合理、方便的参数形式,进而倒推我们设计递归函数。