
图的遍历以及适配器
图的表示方法
参见图的存储结构|邻接矩阵、邻接表、十字链表、邻接多重表、边集数组
正由于图的表示方法多种多样,各种题目给出的图结构也大不相同,我们难以同时熟练掌握这么多结构。但是,我们可以很容易地将其他图结构转换成自己熟悉的图结构,然后在此基础上解题,就会显得更有把握。下面的适配器就是用于此目的。
适配器
我们自己定义的图结构是最形象,功能最全面的结构,包含图、节点和边,如下:
struct graphEdge;
struct graphNode
{
int value;
int in; //入度
int out; //出度
list<graphNode*> nexts; //邻点(指出去)
list<graphEdge*> edges; //邻边(指出去)
graphNode(int _value):value(_value), in(0), out(0){}
};
struct graphEdge
{
int weight;
graphNode* from;
graphNode* to;
graphEdge(int _weight, graphNode* _from, graphNode* _to):weight(_weight), from(_from), to(_to){}
};
struct graph
{
unordered_map<int, graphNode*> nodes;
unordered_set<graphEdge*> edges;
};
注意!该图是有向图,graphNode 中的 nexts 和 edges 都是指出去的对象,并不含指进来的对象!
graph 中的 nodes 为什么是 unordered_map<int, graphNode*> ?因为我们一般用整形来指代节点,而 graphNode 是自己定义的结构,它对客户是不透明的,所以必须建立映射关系。
在算法面试中,常见的图结构表示如下:
[weight, from, to]
这表示从 from 节点指向 to 节点,且边的权重为 weight,一个二维数组即可表示整张图:
vector<vector<int>> nodes = {{0,1,2},
{0,1,3},
{0,2,3},
{0,2,4},
{0,2,5},
{0,3,4},
{0,4,5},
{0,5,3}};
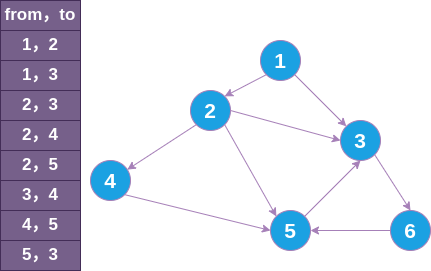
以该结构为例,将其转换为 graph 结构,适配函数如下:
graph graphAdaptor(vector<vector<int>> _graph)
{
graph gra;
int weight;
int from;
int to;
for(int i = 0; i < _graph.size(); i++)
{
weight = _graph[i][0];
from = _graph[i][1];
to = _graph[i][2];
if(gra.nodes.find(from) == gra.nodes.end())//易忽略,没有才加入
{
graphNode* node = new graphNode(from);
gra.nodes.emplace(from, node);
}
if(gra.nodes.find(to) == gra.nodes.end())
{
graphNode* node = new graphNode(to);
gra.nodes.emplace(to, node);
}
graphNode* nodeFrom = gra.nodes.at(from);
graphNode* nodeTo = gra.nodes.at(to);
graphEdge* edge = new graphEdge(weight, nodeFrom, nodeTo);
nodeFrom->edges.push_back(edge);
nodeFrom->out++;
nodeTo->in++;
nodeFrom->nexts.push_back(nodeTo);
gra.edges.emplace(edge);
}
return gra;
}
当然,我们的图结构对某些题目而言可能存在冗余信息,不要紧,不用的信息直接忽略,只在适配器函数中初始化我们想要的信息即可。
图的深度优先遍历
思想很简单,唯一需要注意的是,必须保证已经访问过的节点不再访问,否则将无限递归。
void graphDFS_in(graphNode* node, unordered_set<graphNode*> &accessed)//注意这里必须引用!作为全局对象
{
if(accessed.find(node) != accessed.end())//如果已经访问过,则返回
return;
std::cout << node->value << ", ";
accessed.emplace(node);
auto p = node->nexts.begin();
while(p != node->nexts.end())
{
graphDFS_in(*p, accessed);
p++;
}
}
void graphDFS(graphNode* node)
{
if(node == nullptr)
return;
unordered_set<graphNode*> accessed;
graphDFS_in(node, accessed);
std::cout << std::endl;
}
以上是递归实现,简洁易懂,下面看看迭代版本:
void graphDFS_stack(graphNode* node)
{
stack<graphNode*> stk;
unordered_set<graphNode*> set;
graphNode* tmp;
stk.push(node);
set.emplace(node);
std::cout<< node->value << ", ";
while(!stk.empty())
{
tmp = stk.top();
stk.pop();
for(auto n : tmp->nexts)
{
if(set.find(n) == set.end())
{
stk.push(tmp);
stk.push(n);
set.emplace(n);
std::cout<< n->value << ", ";
}
}
}
std::cout << std::endl;
}
图的广度优先遍历
和树的层序遍历相同,仍然使用队列进行 BFS ,但仍须注意已经访问过的节点不能再次访问。
void graphBFS(graphNode* node)
{
if(node == nullptr)
return;
graphNode* tmp;
queue<graphNode*> que;
unordered_set<graphNode*> accessed;
que.push(node);
accessed.emplace(node);
while(!que.empty())
{
tmp = que.front();
que.pop();
std::cout << tmp->value << ", ";
auto p = tmp->nexts.begin();
while(p != tmp->nexts.end())
{
if(accessed.find(*p) == accessed.end())
{
que.push(*p);
accessed.emplace(*p);
}
p++;
}
}
std::cout << std::endl;
}
注意,当图为非连通图时,以上方法无法遍历所有节点;对非连通图,需要以每个节点为起点都遍历一次,才能遍历完所有节点。
版权声明:
本站所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自
后端技术分享!
喜欢就支持一下吧