
加载内核-代码详解
前置内容:浅析C语言和汇编混合编程
本节对应分支:load-kernel
概览
让我们看看目录结构:
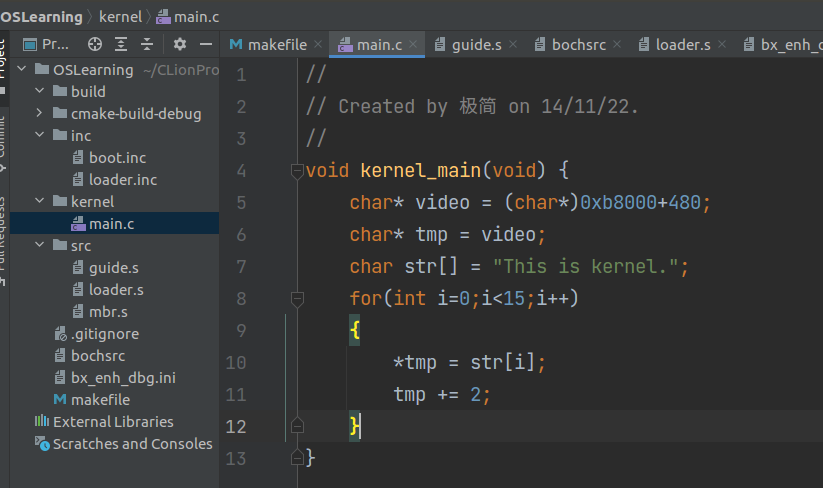
相比 open-page 分支,本分支新增了两个文件,一个是 /kernel/main.c (如上),另一个是 /src/guide.s :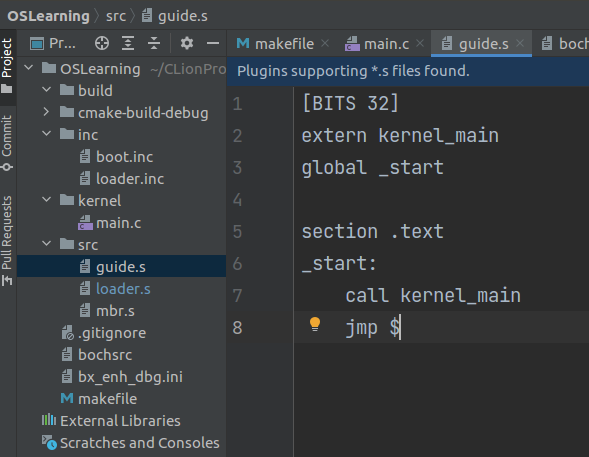
loader.s 作了改动,下面是分支 load-kernel 相对于 open-page 的修改:
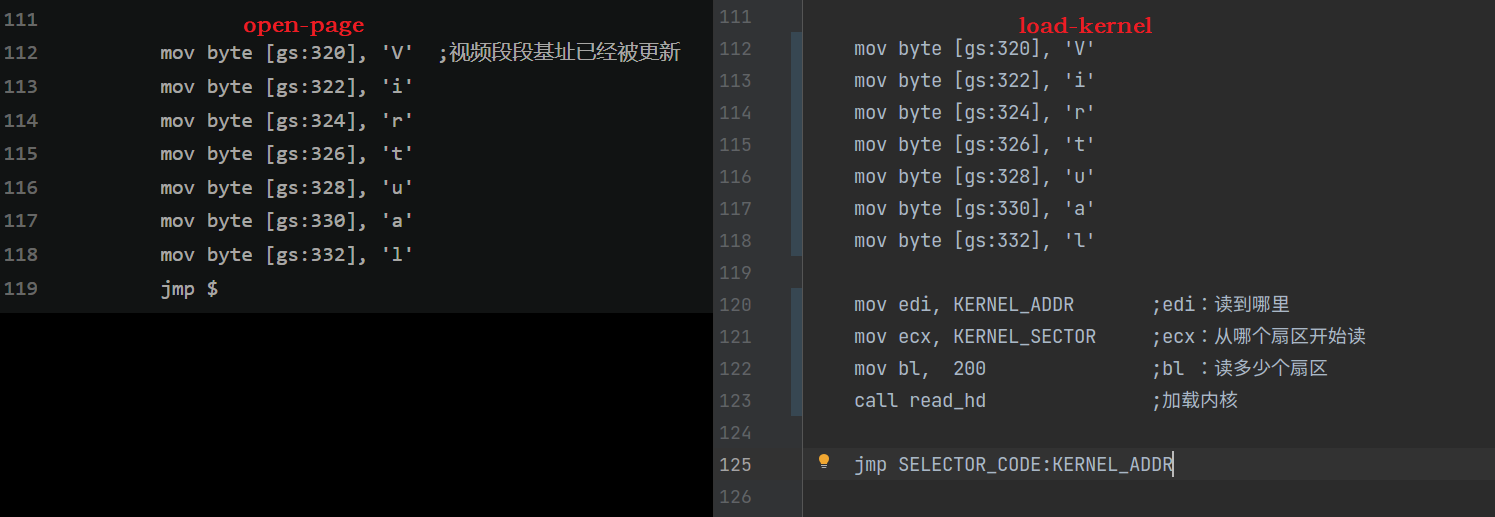
显然,load-kernel 从硬盘中读取内核并加载到 KERNEL_ADDR 地址处,最后跳转进入内核,loader 使命到此结束 。
loader 的使命虽然结束了,但里面的 GDT 我们可还要用呢,后面注意不能把 loader 覆盖,即使要覆盖,也必须先转移 GDT。
为什么需要引导文件?
容易知道,main.c 就是内核。按之前编写 mbr.s 和 loader.s 的经验,我们可能会想到直接将 main.c 编译成 main.bin 文件,然后将 main.bin 直接加载到内存 KERNEL_ADDR 处,接着再跳转进入内核,这不就大功告成了吗?那么为啥还得先进入 guide.s ,然后再调用内核 kernel_main?感觉它很鸡肋啊…嗯,这个问题也困扰了我好一会。其实,前面这个想法很容易被否定,原因在于,你怎么能保证 main.bin 文件的开头一定是 kernel_main 函数的入口而不是其他描述信息 ?注意看,kernel_main 函数里面可也是定义了数据的,所以你又怎么保证 main.bin 文件的开头是指令还是数据 ?综上,直接将 main.bin 加载到某个位置并跳转过去,这个方案是不可取的。你可能又会说,kernel_main 函数中不就定义了两个 char* 指针和一个字符串吗,char* 四字节,字符串 15 字节,总字节数为4+4+15=23 ,那么在 loader 中跳转时,我越过这个 23 字节,直接跳到代码处不就行了?哈哈哈,我一开始也这么想过,不过马上就否定了。我们会产生这种想法的原因在于之前 loader 和 mbr 都是用汇编写的(也只能用汇编),而汇编能让我们掌握程序的每一个细节。可 C 语言这种高级语言呢?它虽然大大简化了程序的编写难度,但却对上层屏蔽了很多细节,这些细节我们很难完全把控。所以,由 main.c 转换 main.s 时,你并不清楚 main.s 中的内存布局 。所以,这个想法也被否定啦。因此,我们使用引导文件 guide.s 来引导(guide)程序进入内核。
其实,guide.s 也是可以省略的,我们只需要把 kernel_main 的名字改为 _start ,这样编译器就能识别,并将其作为程序入口。
编译链接解析
方案确定了,那么这个引导过程是如何进行的呢?首先,我们将 main.c 和 guide.s 编译为可重定位文件并链接,具体命令见以下 makefile(简化后):
BUILD= ./build
SRC=./src
CFLAGS:= -m32 # 32 位的程序
CFLAGS+= -masm=intel # 采用intel汇编语法
CFLAGS+= -fno-builtin # 不需要 gcc 内置函数
CFLAGS+= -nostdinc # 不需要标准头文件
CFLAGS+= -fno-pic # 不需要位置无关的代码 position independent code
CFLAGS+= -fno-pie # 不需要位置无关的可执行程序 position independent executable
CFLAGS+= -nostdlib # 不需要标准库
CFLAGS+= -fno-stack-protector # 不需要栈保护
CFLAGS:=$(strip $(CFLAGS))
$(BUILD)/pure_kernel.bin: $(BUILD)/kernel.bin
objcopy -O binary $(BUILD)/kernel.bin $@
$(BUILD)/kernel.bin: $(BUILD)/guide.o $(BUILD)/main.o
ld -m elf_i386 $^ -o $@ -Ttext 0x00001500
$(BUILD)/main.o: ./kernel/main.c
gcc $(CFLAGS) -g -c $< -o $@
$(BUILD)/guide.o: $(SRC)/guide.s
nasm -f elf32 -g $< -o $@
-
第 24~25 行,将 guide.s 编译为 guide.o(可重定位文件) 。注意编译选项:
-f:大家对这个应该很熟悉了吧,即指定文件输出格式。这里的输出格式为elf32,目的是待会要和 gcc 编译的 elf 格式的目标文件链接,所以格式必须相同 。-g:添加调试信息。这点对我们后面调试内核至关重要 !如果你编程能力极强,完全不需要调试,一眼就能看出错误(手动狗头),那可以忽略该选项。-o:不必多说,指定输出文件的名称。
-
第 21~22 行,将 main.c 编译为 main.o(可重定位文件) 。注意编译选项:
$(CFLAGS):上面一大堆的 gcc 配置,这非常重要 !这是在指示 gcc 不要生成其他无关的东西,我只要 main.c 中的原生汇编代码,别瞎搞。因为一般 .c 文件编译成 .o 文件后都会增加大量描述信息和其他库代码,现在我们不需要这个。-g:和之前一样,添加调试信息,用于内核调试。-c:只生成可重定位文件。如果不加该选项,会直接生成可执行程序。-o:指定输出文件的名称。
-
第 17~18 行,链接 guide.o 和 main.o 。注意链接选项:
-
-m:指定输出格式为 elf_i386 。 -
-Ttext:指示代码的起始地址。也就是说,你将内核加载到哪个地方,选项后就跟哪个地址;由于 loader.inc 中的KERNEL_ADDR为 0x1500,所以这里也为 0x1500。这个选项的作用和 vstart 完全相同 !所以基础可不能落下,不明白 vstart 的朋友请回 程序加载器。由于我们已经开启了分页,所以按理来说指定起始地址时也必须指定虚拟地址 !但是,还记得之前我们已经将第 0 号页表的地址同时写入了第 0 号和第 768 号目录项中吗?所以 目前 这里填 0x1500 或 0xc0001500 都没有问题。目前没有问题?以后就有问题啦?是的,未来我们会回到此处并解析这个问题。
-
-
第 14~15 行,将 kernel.bin 中最原生的代码段和数据段抠出来,放入 pure_kernel.bin 中。
现在的 kernel.bin 是 ELF 格式,其中含有大量的描述信息(程序头,节头等)和调试信息,而这些是 CPU 看不懂的,不能直接把该文件交给 CPU 运行。所以使用 objcopy 命令,只将其中的代码段和数据段抠出来,并整理到 pure_kernel.bin 中,这才是 CPU 能够运行的文件。关于 objcopy 可参考objcopy命令 。
-O binary:指定输入目标为二进制文件。
说实话,这些配置是很难找的,至少整个中文网上都是找不到的,即使找到相关介绍,你也不知道怎么去使用。此处的配置由子牙老师提供,笔者在此表示感谢,这至少让我们省了一个月的精力。
说了这么多,大家有没有对这个引导过程产生一点感觉?好吧,挑明了讲,由于 _start 是默认的程序入口地址(这点已在本节前置文章中讲过),所以可以料到,objcopy 后,pure_kernel.bin 文件的开头就是 guide.s 中 _start 标号处的指令 ,即 call kernel_main 。又因为我们指定了代码的起始地址(-Ttext 0x1500),所以 call kernel_main 指令的地址就为 0x1500 。这样,当我们把内核加载到内存 0x1500 后,就可以由 loader 中的最后一条指令 call SELECTOR_CODE:KERNEL_ADDR 跳转到 0x1500 处,然后调用内核。
你不信 pure_kernel.bin 文件的开头是指令 call kernel_main ?那我们就看看 pure_kernel.bin 长什么样: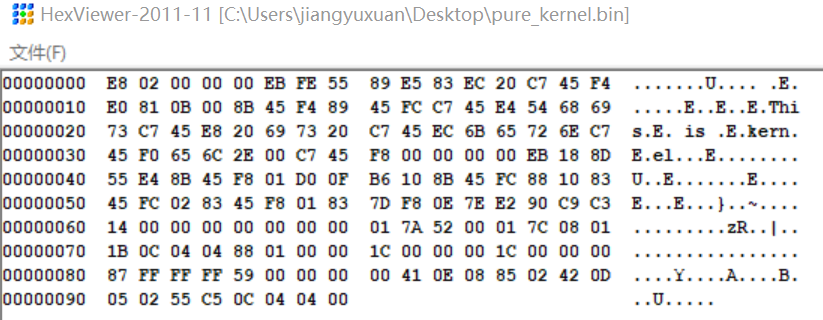
看见开头的 E8 02 没?这就是近转移指令 call kernel_main 。这下信了吧,哈哈。
其他说明
count参数
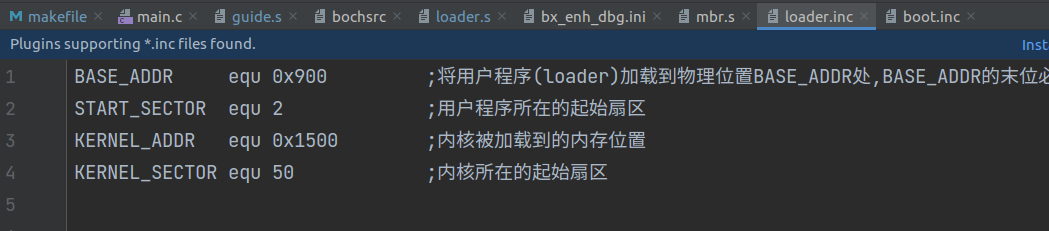
这是 loader.inc 文件:
以下是 makefile 中写入硬盘的部分:
./$(DISK):$(BUILD)/mbr.bin $(BUILD)/loader.bin $(BUILD)/pure_kernel.bin
bximage -q -hd=16 -func=create -sectsize=512 -imgmode=flat $@
dd if=$(BUILD)/mbr.bin of=$@ bs=512 conv=notrunc
dd if=$(BUILD)/loader.bin of=$@ bs=512 seek=2 conv=notrunc
dd if=$(BUILD)/pure_kernel.bin of=$@ bs=512 seek=50 count=200 conv=notrunc
看最后一行,seek=50 表示跳过 50 个扇区,从第 50 个扇区(起始为0)开始写,这对应了第四行 inc 配置。但为什么 count=200 ?即一次写入 200 个扇区?这是因为后面我们的内核会越来越大,每次更新完内核需要向硬盘中同步,而我们可能会忘记修改 count,导致内核写入不全,所以一次性把 count 设置大一点。额,好吧,其实最方便的是直接不加 count,文件有多大就写多大,这不香嘛?
显存
有人可能不太明白 kernel_main 函数中的第一行 0xb8000 后为啥加上 480,这是因为我们现在的显示模式是 25×80 的文本显示模式,每行 80 个字,25 行,所以一屏最多容纳 2000 字。一个字符占两个字节,第一字节是 ASCII 码,第二字节是字符属性(颜色,闪烁等),所以如果我们要从第 4 行开始打印,则地址就应该为 0xb8000+80×2×3 ,即 0xb8000+480 。
0xb8000 是啥就不必多说了吧。。。
char与short
为了使大家更深刻地理解指针,笔者对 kernel_main() 做了如下修改:
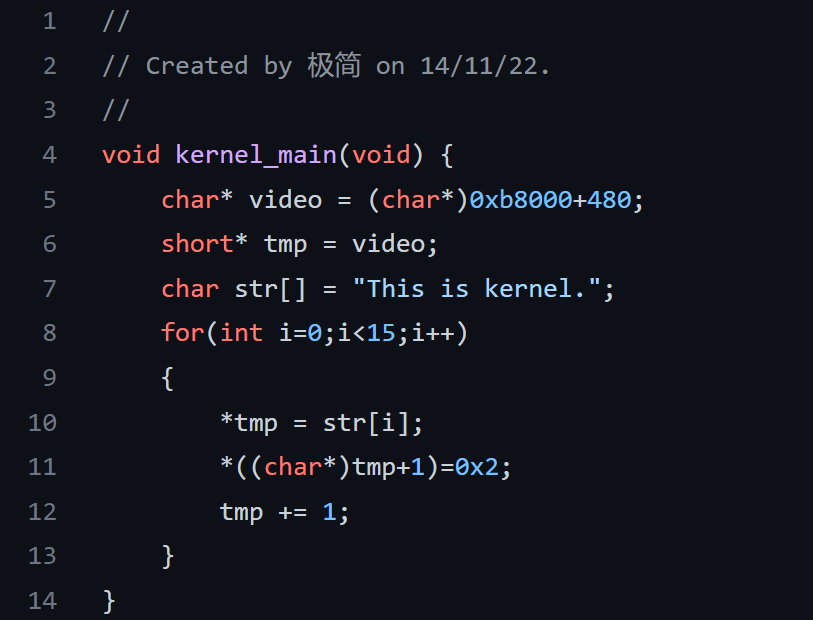
第 11 行的 0x2 代表字符属性,黑底绿字。代码含义请读者自行思考。
运行结果
-Ttext 0x1500 或 -Ttext 0xc0001500 都得到如下结果:
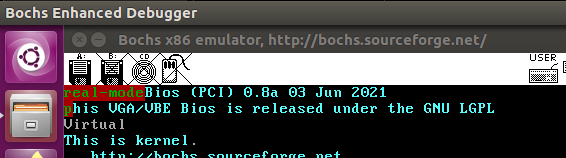
到此为止,我们已经分别在实模式、保护模式、开启分页后、加载内核后打印了信息。
运行方式:转到 makefile 下,点击顺序:clean --> all --> bochs