
printf底层剖析及可变参数探究
本文前置内容:可变参数列表
本文参考文章:《你必须知道的495个C语言问题》《Linux内核完全注释》《操作系统真相还原》printf-菜鸟教程
本节对应分支:printk
概览
相信每一位 C 选手写下的第一句代码都是下面这句经典的 Hello World 吧?
int main()
{
printf("hello world!");
return 0;
}
理所应当的,其中的 printf 函数也成为了咋们认识的第一个函数。对笔者个人而言, printf 是一个熟悉而陌生的函数,说熟悉是因为它伴随了我整个 C 语言的学习生涯;说陌生是因为学习过程中一直对它存疑,模模糊糊,始终没能一探究竟,不知道各位读者是否也是像笔者一样呢?记得 C 语言萌新阶段时,我时常吐槽 printf 中的那些格式符,如 %d、%s、%c、%x 等,乱七八糟的,实在是太难记啦!入门阶段时,我赞叹 printf 强大的格式处理能力,比如左右对齐、输出宽度、输出精度等;进阶阶段时,我又开始疑惑 printf 是如何做到参数可变的,但因为基础不足,就暂时搁浅。现在,天时地利人和,让我们对 printf 一网打尽吧!
本文将从以下几个方向逐个击破 printf :
- 默认参数提升
- 可变参数的类型检查
- 可变参函数实现原理
- 其他注意事项
- printf源码详解
默认参数提升
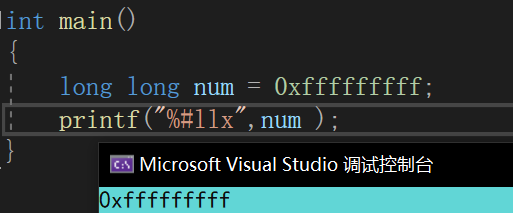
注意,默认参数提升仅对可变参数列表有效 ,其规则是:char 和 short 自动提升为 int,float 自动提升为 double 。
比如我们一定知道,%f 用来输出 float,%lf 则用来输出 double;但实际上 %f 可以同时表示 float 和 double 类型,而无需专门指定 %lf 来表示 double(因为 printf 只能看到双精度),如下图:

本操作系统未支持浮点(难度较大,非常麻烦),且笔者对浮点的硬件支持不太了解,所以下面不讨论浮点。
将 char/short 提升为 int 的原因是:可变参函数的原型无法提供参数个数以及参数类型,所以编译器无法针对各个参数生成相应代码,因此只好统一为 int 类型 。
比如
printf的原型为:int printf(const char * fmt, ...)显然,
...(即可变参数列表)无法提供参数的个数和类型。值得一提的是,printf中的f就是指的format。
这么说原因大家可能还不太明白什么意思,下面笔者用代码进行解释,先来看普通函数:
void test(int a, short b, char c);
int main()
{
int a = 1;
short b = 2;
char c = 3;
test(a,b,c);
}
void test(int a, short b, char c)
{
a=10,b=11,c=12;
}
该文件生成的反汇编为:
00000000 <main>:
0: 8d 4c 24 04 lea ecx,[esp+0x4]
4: 83 e4 f0 and esp,0xfffffff0
7: ff 71 fc push DWORD PTR [ecx-0x4]
a: 55 push ebp
b: 89 e5 mov ebp,esp
d: 51 push ecx
e: 83 ec 14 sub esp,0x14
11: c7 45 f4 01 00 00 00 mov DWORD PTR [ebp-0xc],0x1
18: 66 c7 45 f2 02 00 mov WORD PTR [ebp-0xe],0x2
1e: c6 45 f1 03 mov BYTE PTR [ebp-0xf],0x3
22: 0f be 55 f1 movsx edx,BYTE PTR [ebp-0xf]
26: 0f bf 45 f2 movsx eax,WORD PTR [ebp-0xe]
2a: 83 ec 04 sub esp,0x4
2d: 52 push edx
2e: 50 push eax
2f: ff 75 f4 push DWORD PTR [ebp-0xc]
32: e8 fc ff ff ff call 33 <main+0x33>
37: 83 c4 10 add esp,0x10
3a: b8 00 00 00 00 mov eax,0x0
3f: 8b 4d fc mov ecx,DWORD PTR [ebp-0x4]
42: c9 leave
43: 8d 61 fc lea esp,[ecx-0x4]
46: c3 ret
00000047 <test>:
47: 55 push ebp
48: 89 e5 mov ebp,esp
4a: 83 ec 08 sub esp,0x8
4d: 8b 55 0c mov edx,DWORD PTR [ebp+0xc]
50: 8b 45 10 mov eax,DWORD PTR [ebp+0x10]
53: 66 89 55 fc mov WORD PTR [ebp-0x4],dx
57: 88 45 f8 mov BYTE PTR [ebp-0x8],al
5a: c7 45 08 0a 00 00 00 mov DWORD PTR [ebp+0x8],0xa
61: 66 c7 45 fc 0b 00 mov WORD PTR [ebp-0x4],0xb
67: c6 45 f8 0c mov BYTE PTR [ebp-0x8],0xc
6b: 90 nop
6c: c9 leave
6d: c3 ret
从第 34~36 行就可以看出参数类型的区别:int、short、char 对应的反汇编分别为 DWORD、WORD、BYTE ,也就是说,编译器为不同的类型生成了不同的代码。
笔者以前想当然地认为函数参数类型影响的是压栈的字节数,比如将 char 压入栈,对应的反汇编就应该为
push BYTE PTR [xxx];实际上并非如此,不论是 char、short、int 或是 long、long long,编译器都会压入 4 字节(对于 long long 8 字节,分两次压入) ,这点从 15~17 行就能体现。所以参数类型影响的不是压栈,而影响的是从栈中取值或赋值。
那么对于可变参数列表,默认参数提升是如何体现的呢?待会讲解 printf 源码时再回过头来说这点。
可变参数的类型检查
还是由于可变参数列表无法提供参数类型,所以编译器无法对参数进行类型检查,换句话说,编译器不能执行默认的类型转换,通常也不会报错 。对于普通函数而言,如果实参和形参类型不匹配,编译器会将实参隐式转换为形参类型,如下:
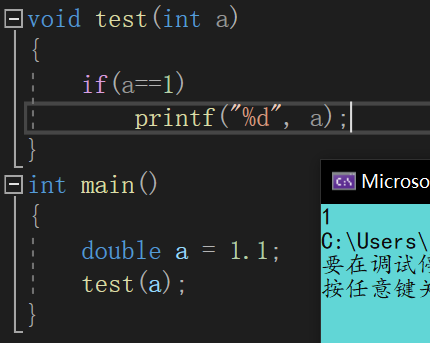
而对于可变参数函数,编译器则无法将实参隐式转换为形参类型,如下:

所以程序员必须自己确保参数类型的匹配或手动强制转换。
可变参数函数实现原理
想要实现可变参数,最重要的是明白其函数的调用方式,如果没有特定的函数调用约定,可变参数将无从谈起。可变参数函数的调用方式必须满足以下两个条件:
-
从右向左压栈
为什么要从右往左入栈? 因为如果从左向右,编译器就不知道用户传入了多少实参。参数的信息是由第一个参数
fmt...确定的(如printf (“% s % s”,str1 ,str2)的参数信息是通过检测两个%s来获取的)。若从左向右压栈,fmt...就被放入了栈底,而 esp 由于不清楚参数个数和类型,就无法跨过这些参数来指向fmt...,因此无法获取各个参数的信息。相反,若从右向左压栈,fmt...就存放在栈顶,这样就可以直接通过它得知参数的个数和类型,进而准确从栈中取得各个参数。 -
外平栈(调用者平栈)
必须由调用者平栈的原因是:只有调用者才知道压入了几个参数,所以也只能由调用者进行平栈。读者可能感到疑惑,为什么只有调用者才知道压入了几个参数?仍然拿
printf举例,是这样的:printf作为库函数,是提前被编译好了的(一般作为动态链接库),最后直接与我们自己编写生成的可重定位文件链接在一起,从而生成可执行文件;所以printf完全不知道实际压入了多少个参数(因为压参是由我们的编译器进行的)!因此也就无法由printf自己来完成平栈。相反,如果是调用方本身来调用的printf,理所应当地,调用方就知道自己向栈中压入了多少个参数,所以调用方就可以承担平栈任务,如下代码:int main() { printf("%d %c", 1, 2); } //对应汇编: //......省略 00BF17E1 push 2 00BF17E3 push 1 00BF17E5 push offset string "%d\n" (0BF7BD8h) 00BF17EA call _printf 00BF17EF add esp,0Ch //......省略call 之前,编译器 push 了三次,所以它当然知道平栈需要 add esp,0xC !而 printf 是已经编好的库,它就不知道 push 了几次。
而 __cdel 调用约定就符合以上两个规则,所以可变参函数必须使用此方式。值得一提的是,__cdel 是 C/C++ 默认方式。
有了以上两种条件的支持,现在无非就是处理 fmt... 获取参数信息,然后从栈中取得参数即可。这就是咋们接下来要干的事。
其他注意事项
需要打印%咋办?
这点相信大部分读者都清楚,打印百分号需要再加个百分号,如下:
printf("这是百分号%%");
很多小白会在 % 前加 \ ,即 printf("\%") 来输出百分号。出现这种想法是因为没有理解转义字符的意义,要知道,\n 是一个 ASCII 码(10),由编译器负责将 \n 转为 10 。而 \% 可不是转义字符,对 % 的处理是由我们的代码负责,而不是由编译器负责!
printf实参问题
很多读者应该都像下面这种方式调用过 printf 吧:
printf("%d",110);
这种方式有什么不对吗?结果正确,但这种调用方式十分危险。这是因为,110 没有指明类型,所以根据前面的默认参数提升,110 被视为 int,这符合 %d ,所以能够正确输出。但是碰到下面这种情况呢?
printf("%lld",110);
结果就变得诡异,输出如下:
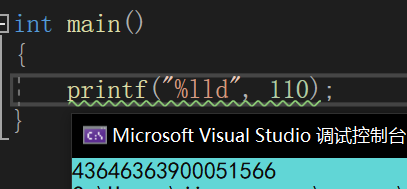
这是因为 110 被编译器视为 int(4字节),但 printf 内部代码根据 %lld 将 110 视为 long long(8字节),在定位参数时,将 long long* 指针指向 110 所在的位置,那么用该指针解释数据的时候,将会把 110 后面的四字节包含进去,而这四字节中的数据是未定义的,所以造成以上错误。再来看下面的调用:
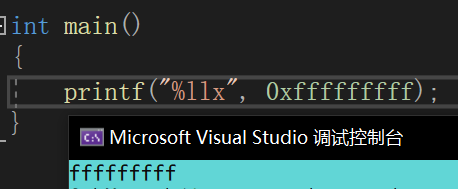
怎么这种情况又能够正确显示呢?这是因为编译器判定 0xfffffffff 无法用 int 装下,所以该值的类型就变为了 long long,因此能够正确输出。正确的调用方式需要加上强制转换:
printf("%lld",(long long)110);
看完 printf 源码后,你会对上述行为有深刻理解。
printf源码剖析
说明:
- 以下源码来自 Linux 0.11 ,也就是 Linus Torvalds 编写的初代 Linux ,所以其功能肯定不如现在的 printf 强大,这点读者需要清楚。
- printk(print kernel)和 printf 的功能完全相同,只不过前者是在内核中使用的打印函数,而后者是在用户态中使用的打印函数。
- 为了契合咋们的操作系统,笔者会将 printk 作轻微修改,使其能够在用户态下使用(此时也就变成了 printf ),这不会影响对 printf 的理解。
以下是原版的 printk :
static char buf[1024];
int printk(const char *fmt, ...)
{
va_list args;
int i;
va_start(args, fmt);
i=vsprintf(buf,fmt,args);
va_end(args);
__asm__("push %%fs\n\t"
"push %%ds\n\t"
"pop %%fs\n\t"
"pushl %0\n\t"
"pushl $_buf\n\t"
"pushl $0\n\t"
"call _tty_write\n\t"
"addl $8,%%esp\n\t"
"popl %0\n\t"
"pop %%fs"
::"r" (i):"ax","cx","dx");
return i;
}
提供原版的 printk 只是为了与下面咋们改进后的 printf 形成对比,大家无需纠结上面的代码。以下是我们操作系统的 printf :
static char buf[1024];
int printf(const char * fmt, ...)
{
va_list args;
int i;
va_start(args, fmt);
vsprintf(buf, fmt, args);
va_end(args);
int i = write(buf);
return i;
}
- 可见,除了第 9 行外,其他完全相同。实际上,第 9 行将最终的字符串传给我们之前实现的系统调用 write,由 write 进行打印。另外,正因为 write 是系统调用,所以该 printf 既可以供内核使用,也可以供用户使用 。
printf返回字符个数。
接下来重点说明处理可变参数的四个宏: va_list 、va_start 、va_end 和 va_arg 。
可变参数宏
首先要破除大家的先入为主,别以为这四个宏是用来处理可变参数的,就觉得它们高大上,有什么特异功能,实际上这四个家伙的本质就普普通通:
typedef char* va_list;
#define va_start(p, fmt) (p = (char*)&fmt + sizeof(char*))
#define va_end(p) (p = 0)
#define va_arg(p, type) (p += __va_rounded_size(type), *((type*)(p - __va_rounded_size (type))))
-
va_list就是 char 指针类型,该指针(args)用来在栈中依次遍历各个参数* 。 -
va_start的作用是将 args 指针指向参数列表(即...)中的第一个参数 。p = (char*)&fmt + sizeof(char*)就是令 p 跳过栈中的 fmt ,指向栈中的下一个参数,即参数列表中的第一个参数。注意必须对 fmt 取地址,得到该指针的地址,也就是该指针在栈中的位置,&fmt为二级指针,还需要强制转换为一级指针 char* 。 -
va_end的作用是将 args 指针置 NULL 。 -
va_arg出现在下面的vsprintf函数中,va_arg的作用是返回当前 args 指向的参数的值,然后 args 向后移动,指向下一个参数 。__va_rounded_size(type)也是一个宏,用来得到取整后的 type 类型的大小,是 int 的整数倍 ,比如 type 为 char,则返回 4;type 为 long long,则返回 8 ,其实现如下:#define __va_rounded_size(type) \ (((sizeof (type) + sizeof (int) - 1) / sizeof (int)) * sizeof (int))注意,va_arg 宏定义是一个逗号表达式,第一个表达式根据目前所指参数 A 的大小,将指针 p 移向了下一个参数 B(+=,p的值已经被改变);接着将 A 的值返回(逗号表达式中的最后一个式子作为返回值)。顺便提一下,如果按照《操作系统真相还原》中的代码,将无法应对 long long 的情况。
接着来看 vsprintf 。
vsprintf
vsprintf 的作用是格式化字符串,也就是将参数列表中的所有参数值填入到 fmt 中的对应位置,并将最终的字符串存入 buf 。fmt 中的格式符,如 %d 、%s 等都在此函数中进行处理。在讲解该函数代码前,有必要先复习 printf 的用法,否则看代码时将一头雾水。
我们将 %s 这样的格式称之为一个 format 标签,format 标签的完整格式如下:
%[flags][width][.precision][length]specifier
比如下面这样的 printf 调用:
printf("%-10ld");
其中的 - 为 flags,即指明左对齐;10 为 width,即指明输出宽度;l 为长度,对于 d 而言,即输出长整型 long;d 为 specifier,指明输出整型。
具体规则如下:
| flags | 描述 |
|---|---|
| - | 在给定的字段宽度内左对齐,默认是右对齐 |
| + | 强制在结果之前显示加号或减号(+ 或 -),即正数前面会显示 + 号。默认情况下,只有负数前面会显示一个 - 号。 |
| 空格 | 如果没有写入任何符号,则在该值前面插入一个空格。 |
| # | 与 o、x 或 X 说明符一起使用时,非零值前面会分别显示 0、0x 或 0X。由于本操作系统暂不支持小数,所以不说明 # 对 f、e、g 等说明符的影响。 |
| 0 | 在左边填充零,而不是空格 |
| width | 描述 |
|---|---|
| number | 要输出的字符的最小数目。如果输出的值短于该数,结果会用空格填充;如果输出的值长于该数,结果不会被截断。 |
| * | 宽度在 format 字符串中未指定,但是会作为附加整数值参数放置于可变参数列表中,由该参数指定宽度。 |
| .precision(精度) | 描述 |
|---|---|
| .number | 对于整数说明符(d、i、o、u、x、X):precision 指定了要写入的数字的最小位数。如果写入的值短于该数,结果会用前导零来填充。如果写入的值长于该数,结果不会被截断。精度为 0 意味着不写入任何字符。 对于 s:要输出的最大字符数。默认情况下,所有字符都会被输出,直到遇到末尾的空字符。 对于 c:没有任何影响。 当未指定任何精度时,默认为 1。 |
| .* | 精度在 format 字符串中未指定,但是会作为附加整数值参数放置于可变参数列表中,由该参数指定精度。 |
| length | 描述 |
|---|---|
| h | 参数被解释为短整型或无符号短整型 short(仅适用于整数说明符:i、d、o、u、x 和 X)。 |
| l | 参数被解释为长整型或无符号长整型 long,适用于整数说明符(i、d、o、u、x 和 X)及说明符 c(表示一个宽字符)和 s(表示宽字符字符串)。 |
| L | 参数被解释为长双精度型(仅适用于浮点数说明符:e、E、f、g 和 G)。本操作系统不支持。 |
| ll | 本操作系统中,ll 仅被解释为 无符号 long long,适用于整数说明符。 |
| 格式字符 | 意义 |
|---|---|
| d | 以十进制形式输出带符号整数(正数不输出符号) |
| i | 和 d 完全相同 |
| o | 以八进制形式输出无符号整数(不输出前缀0) |
| x,X | 以十六进制形式输出无符号整数(不输出前缀Ox) |
| u | 以十进制形式输出无符号整数 |
| c | 输出单个字符 |
| s | 输出字符串 |
| p | 输出指针地址 |
| n | 到目前为止成功写入缓冲区的字符数,此值存储在指定的整数中,其地址作为参数给出。 |
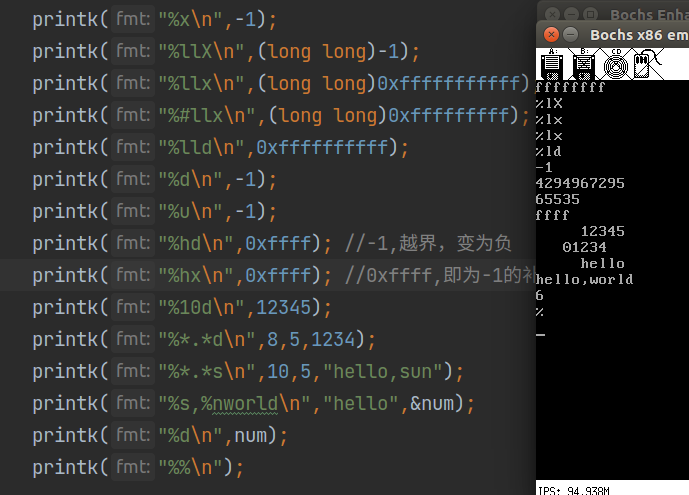
下面做几个示范:
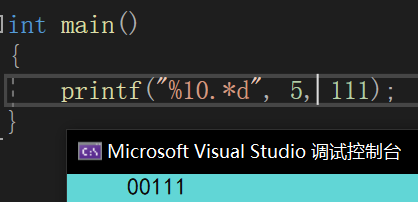
了解以上格式后,再来看 vsprintf 就十分轻松啦,总的来说,该函数就是在依次处理 flags --> width --> .precision --> length --> specifier 。代码如下:
//定义成2的倍数,是因为我们将flag变量视为位图,将属性保存到各个二进制位上
#define ZEROPAD 1 /* pad with zero */
#define SIGN 2 /* unsigned/signed long */
#define PLUS 4 /* show plus */
#define SPACE 8 /* space if plus */
#define LEFT 16 /* left justified */
#define SPECIAL 32 /* 0x */
#define SMALL 64 /* use 'abcdef' instead of 'ABCDEF' */
int vsprintf(char *buf, const char *fmt, va_list args)
{
int len;
int i;
char* str;
char* s;
int *ip;
int flags; // flags to number()
int field_width; // width of output field
int precision; // min of digits for integers; max number of chars for from string
int qualifier; // 'h', 'l', or 'L' for integer fields
for (str=buf ; *fmt ; ++fmt)
{
//如果不是format标签,则直接复制到str
if (*fmt != '%')
{
*str++ = *fmt;
continue;
}
//处理flags
flags = 0;
repeat:
++fmt;
switch (*fmt)
{
case '-': flags |= LEFT; goto repeat;
case '+': flags |= PLUS; goto repeat;
case ' ': flags |= SPACE; goto repeat;
case '#': flags |= SPECIAL; goto repeat;
case '0': flags |= ZEROPAD; goto repeat;
}
//处理输出宽度
field_width = -1; //默认为-1,即未指示宽度,因为 flag | -1 = flag
if (is_digit(*fmt))
field_width = skip_atoi(&fmt); //skip_atoi将字符转为数字,后文给出
else if (*fmt == '*')
{
fmt++; //源码没有此句,官方承认为bug
field_width = va_arg(args, int); //若字符为*,则width由下一个参数给出
if (field_width < 0) //若宽度参数小于0,则左靠齐,和'-'号效果相同
{
field_width = -field_width;
flags |= LEFT;
}
}
//处理精度
precision = -1;
if (*fmt == '.')
{
++fmt;
if (is_digit(*fmt))
precision = skip_atoi(&fmt);
else if (*fmt == '*')
{
fmt++; //源码没有此句,官方承认为bug
precision = va_arg(args, int); //若字符为*,则precision由下一个参数给出
}
if (precision < 0)
precision = 0;
}
//处理长度描述符符
qualifier = -1;
if (*fmt == 'h' || *fmt == 'l' || *fmt == 'L')
{
qualifier = *fmt; //实际上,后面就没有用到qualifier了,显得鸡肋
++fmt;
}
//处理格式字符
switch (*fmt)
{
case 'c':
if (!(flags & LEFT)) //如果不是左靠齐,则左边补field_width-1个空格
while (--field_width > 0)
*str++ = ' ';
*str++ = (unsigned char) va_arg(args, int);
while (--field_width > 0) //否则后方补空格
*str++ = ' ';
break;
case 's':
s = va_arg(args, char *);
len = strlen(s);
if (precision < 0)
precision = len;
else if (len > precision) //如果字符串长度大于精度,则丢弃超过精度的部分
len = precision;
if (!(flags & LEFT))
while (len < field_width--)
*str++ = ' ';
for (i = 0; i < len; ++i)
*str++ = *s++;
while (len < field_width--)//如果执行了上面的while,此处就不会再执行
*str++ = ' ';
break;
case 'o': //number函数用来将数字转换为字符串
str = number(str, va_arg(args, unsigned int), 8, field_width, precision, flags);
break;
case 'p': //按十六进制输出指针,宽度为8,宽度不足则补前导0
if (field_width == -1)
{
field_width = 8;
flags |= ZEROPAD;
}
str = number(str,(unsigned int)va_arg(args,void*), 16, field_width, precision, flags);
break;
case 'x':
flags |= SMALL;
case 'X':
str = number(str, va_arg(args, unsigned int), 16, field_width, precision, flags);
break;
case 'd':
case 'i':
flags |= SIGN; //%d和%i都是有符号数
case 'u':
str = number(str, va_arg(args, unsigned int), 10, field_width, precision, flags);
break;
case 'n':
ip = va_arg(args, int *);
*ip = (str - buf); //返回目前字符串的宽度
break;
//若格式转换符不是'%,则表示格式字符串有错,直接将一个%写入输出串中;如果格式转换符的位置处还有字符,则也直接将该字符写入输
//出串中,并返回到107行继续处理格式字符串;否则表示已经处理到格式字符串的结尾处,则退出循环。
default:
if (*fmt != '%')
*str++ = '%';
if (*fmt)
*str++ = *fmt;
else
--fmt;
break;
}
}
*str = '\0';
return str-buf;
}
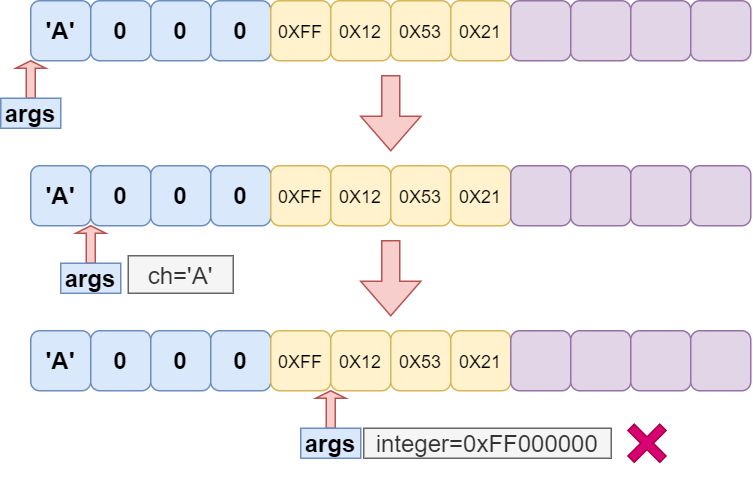
注释得比较清楚,对照之前的规则来看代码就很容易理清其中的逻辑,不再详细说明。提一点,看第 90 行,va_arg(args, int) ,这说明从栈中取字符时,是以 int 大小来取的( 这里就体现了默认参数提升 ),然后再被强制转换为 char 。为什么不能 va_arg(args,char) 呢?实际上这样完全能够准确获取栈中字符的值,但如果这样的话,下一次使用 va_arg 宏取参数时,args 指针就指向了该字符的下一字节,但下一个参数应该是在该字符的四字节后,这无疑将引发错误,图示如下:
代码中还用到了 skip_atoi() 和 number() 函数,代码如下:
#define is_digit(c) ((c) >= '0' && (c) <= '9') //判断是否为数字字符
#define do_div(n,base) ({ \ // n=n/base,并返回n%base
int __res; \ //宏定义采用大括号的方式,最后一条语句作为返回值
__asm__("div %4":"=a" (n),"=d" (__res):"0" (n),"1" (0),"r" (base)); \
__res; })
static int skip_atoi(const char **fmtp)//pointer to fmt,即fmt的指针,所以该指针为二级指针
{ //为什么要用二级指针?因为咋们要在函数中修改fmt的值(不仅是修改形参,实参也要修改)
int i=0; //由于fmt是指针,所以要修改指针的值,就需要用二级指针
while (is_digit(**fmtp))
i = i*10 + *((*fmtp)++) - '0'; //(*fmtp)++,就是fmt++
return i;
}
static char * number(char * str, int num, int base, int size, int precision ,int type)
{
char c,sign,tmp[36];
const char *digits="0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ";
int i;
if (type&SMALL)
digits="0123456789abcdefghijklmnopqrstuvwxyz";
if (type&LEFT)
type &= ~ZEROPAD; //如果为左对齐,则无需0填充
if (base<2 || base>36) //仅支持2~36进制,否则返回
return 0;
c = (type & ZEROPAD) ? '0' : ' ';
if (type&SIGN && num<0)
{
sign='-';
num = -num;
}
else
sign=(type&PLUS) ? '+' : ((type&SPACE) ? ' ' : 0);//要么+,要么空1格
if (sign)
size--; //如果有符号或空格,则占一位
if (type&SPECIAL)
{
if (base==16)
size -= 2; //0x占两位
else if (base==8)
size--; //0占一位
}
// 以下开始处理数字
i=0;
if (num==0)
tmp[i++]='0';
else
while (num!=0)
tmp[i++]=digits[ do_div(num,base) ]; //依次取得num的最低位数字,并填入tmp,
if (i>precision) //此时顺序是反的,第72行会调整顺序
precision=i; //如果数字个数大于精度,不会截断,精度成鸡肋
size -= precision;
if (!(type&(ZEROPAD+LEFT)))
while(size-->0)
*str++ = ' ';
if (sign)
*str++ = sign;
if (type&SPECIAL)
if (base==8)
*str++ = '0';
else if (base==16)
{
*str++ = '0';
*str++ = digits[33]; //'X'或'x',取决于digit的指向
}
if (!(type&LEFT))
while(size-->0) //如果是右靠齐,则补前导0或前导空格
*str++ = c;
while(i<precision--)//精度大于数字个数,则补前导0
*str++ = '0';
while(i-->0)
*str++ = tmp[i];//i--,str++,调整数字顺序
while(size-->0)
*str++ = ' '; //如果67行已经执行,此处就不会再执行
return str;
}
注释详尽,不再说明。
值得一提的是,该版 printf 有许多不足,例如不支持 %hd (short),%lld (long long) ,下节printf加强版中我们会增加这两个功能。
本文结束。