
归并排序变式-区间和计数
问题描述
给定一个数组 arr,两个整数 lower 和 upper,返回 arr 中有多少个子数组的累加和在 [lower, upper] (左闭右闭)范围上。注意,子数组是连续的,单独一个元素也是子数组 。
重要工具 — 前缀和数组
当我们需要 频繁计算 数组中 [l, r] 范围中元素的累加和时,如果每次都要遍历子区间的元素,就显得十分低效,此时前缀和数组就有大用处了。前缀和数组的元素是原数组从 0 下标开始到当前位置所有元素的累加和,比如:arr[4, 8, 6, 10, 12] ,其对应的前缀和数组为:presum[4, 12, 18, 28, 40];当需要计算 arr 的区间 [2, 4] 中的累加和时,只需要用 presum[4] - presum[2-1] 就可得到对应的累加和。原理很好理解,不再过多阐述。
分析
在不使用前缀和数组的情况下,此问题的复杂度将达到 O(N^3) :从下标 0 遍历 N 次 -> 从下标 1 遍历 N-1 次 ->从下标 2 遍历 N-2 次 …每次遍历时,都还需要遍历该范围内的元素以计算累加和。如果使用前缀和数组,就可以将复杂度降低到 O(N^2) 。能不能进一步优化呢?且听下文分析。
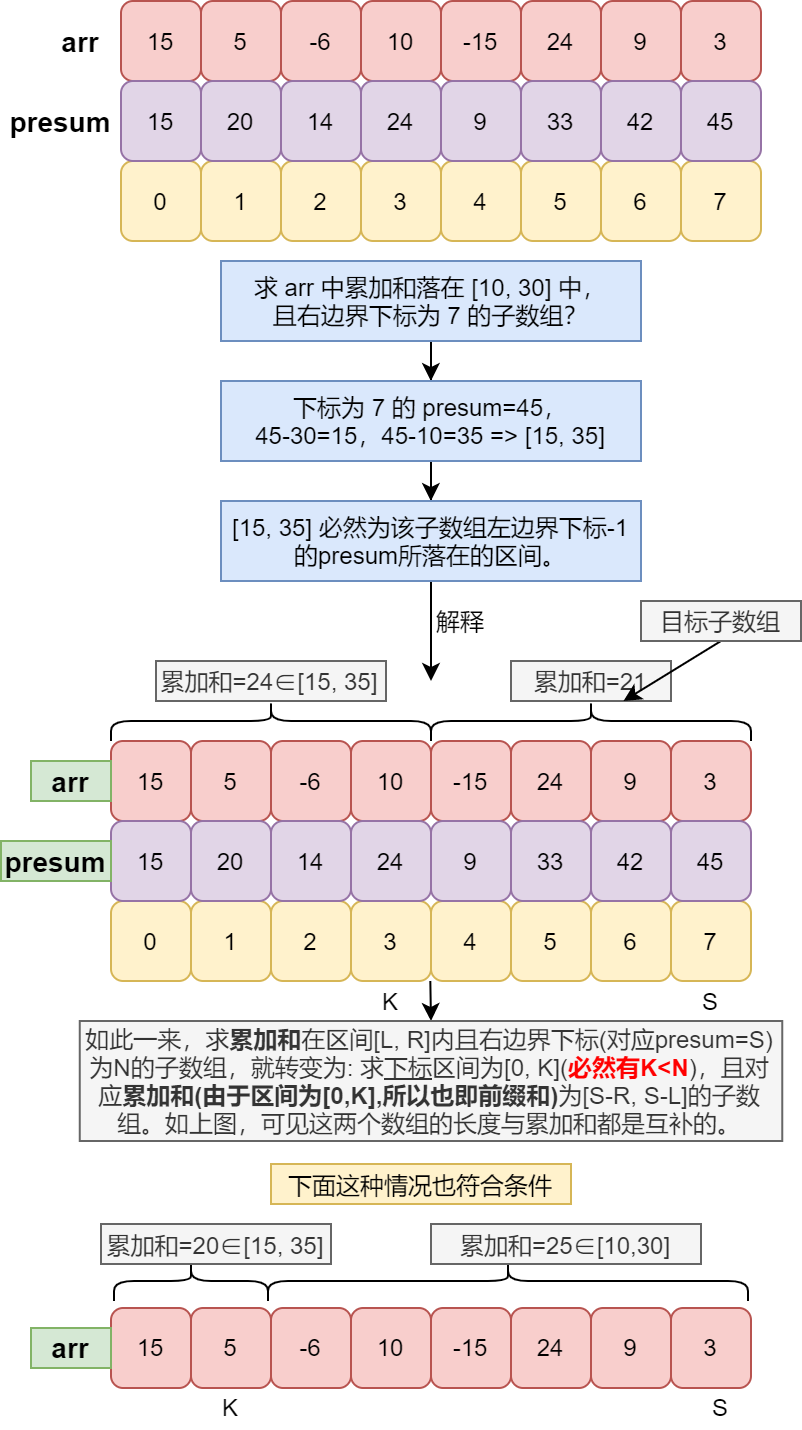
经上图分析,我们成功地将 求累加和在某区间内的子数组个数 转变为了 求前缀和在某区间内的子数组个数 。各位可能仍有疑惑:这与归并排序有什么关系呢?看过博主之前的文章《归并排序及其加强 》的读者也许就会上图中的红色字体有一丝丝感觉。没错,当涉及到一个数组中某个数左(右)边的数与此数的关系时,往往就可以采用归并排序 ,而 必然条件:K<N 就提供了这样一种关系。下面我们再来剖析这个过程(目标区间[10, 30]):
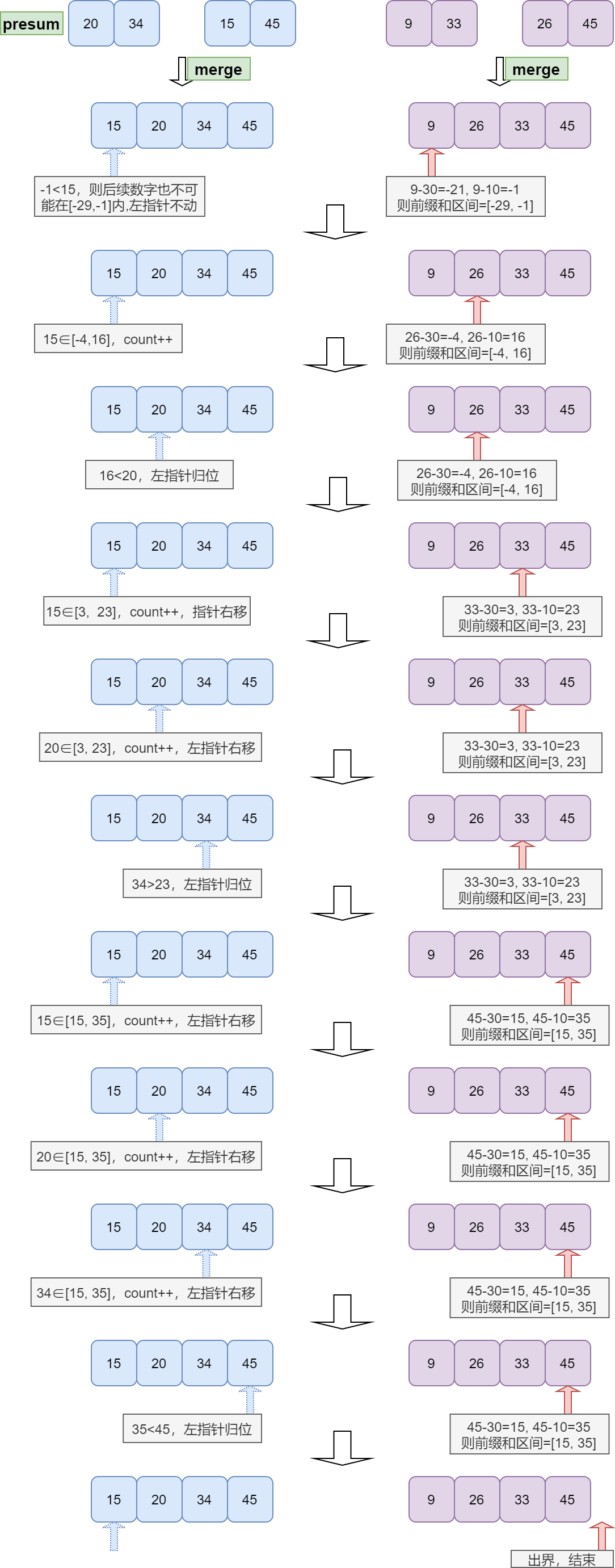
有几个点需要注意:
- 当左边指针指向的数字大于前缀和区间的右边界时,左指针就无需再向右移动,因为其后的数字比当前数字更大,更不可能会落入前缀和区间,所以直接归位到第一个位置。当左边指针指向的数字小于前缀和区间的左边界时,左指针就必须继续向右移动了,这点在图中并未体现,需要留心!
- 此方式下,右边指针始终右移,左边指针则可能回退,所以无法边操作边 merge,只有等到操作结束后统一 merge;类似的还有《归并排序及其加强 》中提到的二倍大问题。
- 由于左指针发生回退,所以此方式复杂度最好情况下才为 O(NlogN) ,而最坏情况下可以达到 O(N^2)
- 为什么能使用归并?因为此方法只关心两个前缀和的相对位置,并不关心它们的具体位置和相距距离。
- 上图的过程中,没有验证某个前缀和本身否落在指定范围,即不能验证 arr 数组从 0 位置到 N 的累加和,而只能验证从 K(K≠0) 到 N 的累加和(即presum[N]-presum[K])。所以还必须单独验证这些前缀和自身是否落在指定范围,此操作在下面代码的 63 行给出。
下面给出代码:
#include<iostream>
#include<cstdlib>//rand()
#include<ctime>//time()
#include<cstring>//memcpy()
#include<vector>
int upper, lower;
int cnt;
void merge(int* arr, int l, int m, int r)
{
int lp = l; //left pointer
int rp = m + 1; //right pointer
while(rp<=r)
{
int prel = arr[rp] - upper;//presum left
int prer = arr[rp] - lower;//presum right
while (true)
{
if (lp > m)
{
rp++;
lp = l;
break;
}
if (arr[lp] < prel)
lp++;
else if (arr[lp] > prer)
{
rp++;
lp = l;
break;
}
else
{
cnt++;
lp++;
}
}
}
int* help = new int[r - l + 1];
int p = 0; //help[]的pointer
lp = l;
rp = m + 1;
while (lp <= m && rp <= r)
help[p++] = arr[lp] < arr[rp] ? arr[lp++] : arr[rp++];
while (lp <= m)
help[p++] = arr[lp++];
while (rp <= r) //第9行和第11行的while只可能进入一个
help[p++] = arr[rp++];
for (int i = 0; i < r - l + 1; i++)
arr[l + i] = help[i];
delete[] help;
}
void process(int* arr, int l, int r)
{
if (l == r)//base case
{
if (arr[l] >= lower && arr[r] <= upper)
cnt++;
return;
}
int m = l + ((r - l) >> 1);
process(arr, l, m);
process(arr, m + 1, r);
merge(arr, l, m, r);
}
void mergeSort(int* arr, int size)
{
if (size == 1)
return;
int r = size - 1;
process(arr, 0, r);
}
int main()
{
lower = 10;
upper = 30;
int arr[4] = {10,1,1,10};
int presum[4] = {0}; //10 11 12 22
for (int i = 0; i < 4; i++)
{
for (int k = 0; k <= i; k++)
presum[i] += arr[k];
}
mergeSort(presum,4);
std::cout << cnt << std::endl;
}
进一步优化
细心观察,我们可以发现,前缀和的上限 prel 与下线 prer 一定是不断增加的,这是因为 prel = arr[rp] - upper,prer = arr[rp] - lower ,而 arr[rp] 是递增的,所以 prel 与 prer 只会增加。所以,[prel, prer] 区间是持续向右移动的,不会回退,我们只需要每次将 [prel, prer] 区间内的数字个数算入 count 即可。过程如下:
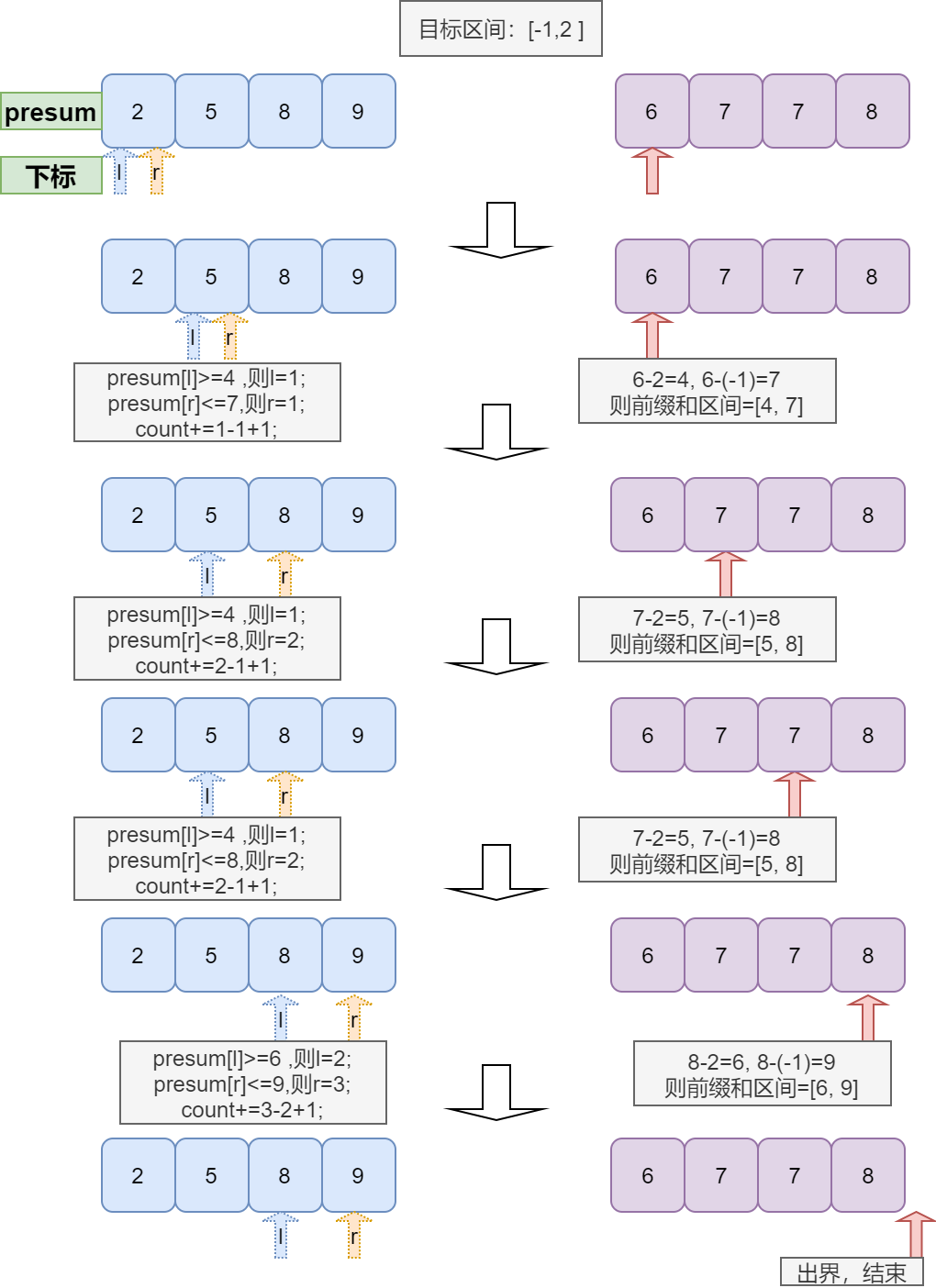
- 注意,l 与 r 是 presum 数组的下标。
- presum[l] 必须紧靠前缀和区间的左边界,presum[r] 必须紧靠前缀和区间的右边界
- 和上一种方式相同,上图并没有验证某个前缀和本身否落在指定范围,需要单独验证。
- count = r + l - 1
- 可见,指针不回退,所以此方法复杂度稳在 O(NlogN) ;
- 仍然先操作完,再统一 merge,否则不好操作;2NlogN 仍然是 O(NlogN) ;
#include<iostream>
#include<cstdlib>//rand()
#include<ctime>//time()
#include<cstring>//memcpy()
#include<vector>
int upper, lower;
int cnt;
void merge(int* arr, int l, int m, int r)
{
int lp = l;
int rp = m + 1;
int wl = l - 1; //window left; wl即图中的l
int wr = l - 1; //window right; wp即图中的r
while(rp <= r)
{
int prel = arr[rp] - upper;//presum left
int prer = arr[rp] - lower;//presum right
while (wl <= m)
{
if (arr[wl] < prel)
wl++;
else break;
}
if (wl > m)
break;
while (wr <= m)
{
if (arr[wr + 1] <= prer && wr!=m)
wr++;
else
break;
}
if (wl != l-1 && wr != l-1)
cnt += wr - wl + 1;
rp++;
}
int* help = new int[r - l + 1];
int p = 0; //help[]的pointer
lp = l;
rp = m + 1;
while (lp <= m && rp <= r)
help[p++] = arr[lp] < arr[rp] ? arr[lp++] : arr[rp++];
while (lp <= m)
help[p++] = arr[lp++];
while (rp <= r) //第9行和第11行的while只可能进入一个
help[p++] = arr[rp++];
for (int i = 0; i < r - l + 1; i++)
arr[l + i] = help[i];
delete[] help;
}
void process(int* arr, int l, int r)
{
if (l == r)//base case
{
if (arr[l] >= lower && arr[r] <= upper)
cnt++;
return;
}
int m = l + ((r - l) >> 1);
process(arr, l, m);
process(arr, m + 1, r);
merge(arr, l, m, r);
}
void mergeSort(int* arr, int size)
{
if (size == 1)
return;
int r = size - 1;
process(arr, 0, r);
}
int main()
{
lower = 10;
upper = 30;
int arr[4] = {0,9,-1,-1};
int presum[4] = {0}; //10 20 30 40
for (int i = 0; i < 4; i++)
{
for (int k = 0; k <= i; k++)
presum[i] += arr[k];
}
mergeSort(presum,4);
std::cout << cnt << std::endl;
}
- 14、15 行为什么设置为 l-1?这是和第 36 行的 if 语句搭配使用的;因为如果 wr 与 wl 初始就指向 l 位置,那么即使 presum[l] 没有落在指定区间,最后也会直接 cnt += wr - wl + 1;这很难把握。
- 21,27,29,31的边界为什么如此设置,留给读者思考,博主仅写此算法就用了一整天,,筋疲力竭。