
初识并查集
并查集(union–find)的核心功能为:
- 查询:判断两个元素是否在同一个集合之中。
- 合并:将两个集合合并为一个。
某些实现可能还允许添加一个新集合。添加操作不如查询和合并操作重要,因此常常被忽略。
任何支持上述两种操作的数据结构都可以称之为并查集 。下面来看看具体操作。
1.初始化并查集
初始状态下,每个元素都作为一个单独的集合:

这里的问题是,如何区分元素与集合?我们需要专门创建一个容器来作为集合吗?并非如此,集合是一个抽象的概念,无需实体支撑。并查集采用的方法是:在每个集合中选出一个代表元素,跟随同一个代表的元素即属于同一个集合。初始状态下,每个元素都是自己集合中的代表。
2.合并
如果要将 2 节点与 1 节点合并为一个集合,让 2 节点指向 1 节点即可(或反之):
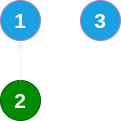
然后我们又将 1 节点所在集合与 3 节点所在集合进行合并,那么我们要面临的问题是:将 1 节点指向 3,还是将 3 节点指向 1 ?
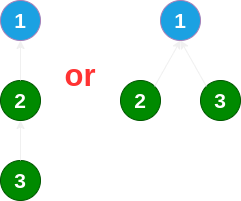
相信大家都会选择将 3 节点指向 1 节点,因为这样“树”的深度更小,直觉告诉我们这样可能更方便后续的查询工作。实际上也是这样做的,为了达到这样的目的,我们就需要为每个集合维护一个 size 值,用来记录该集合中元素的个数。当合并时,将 size 小的代表节点指向 size 大的代表节点,这样就能避免“树”的高度过大。这是并查集的第一个优化,称为合并优化。
size 仅对代表节点有意义
3.查询
查询两个节点是否属于同一个集合,只需要看这两个节点指向的代表是否是同一个节点。
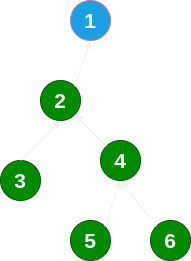
比如判断 3 和 6 是否属于同一个集合,则需要向上遍历直到找到根节点(即代表),然后判断根节点是否相同。仅仅完成这个功能的话,代码则十分简单。问题是,如果数据规模很大,且后续经常查询这两个节点是否属于同一集合,岂不是每一次都要如此重复遍历?那就显得太低效了,我们当然希望之前的查询所花费的努力能够尽可能地为后续查询带来帮助。其实,这种“前帮后”的累积思想也广泛体现在插入排序等算法中。那么具体怎么做?以查询节点 6 为例:
1)来到节点 6 ,先向上遍历找到根节点 1;
2)将节点 6 直接指向根节点 1;
3)来到 6 之前的父节点 4,然后将节点 4 也直接指向根节点 1;
4)来到 4 之前的父节点 2,然后将节点 2 也直接指向根节点 1;
5)来到根节点 1,结束。
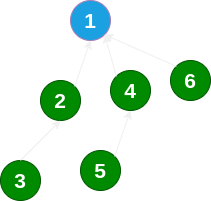
通过这种方式,我们也有效减小了“树”的高度,这是并查集的第二个优化,称为 路径压缩 。注意,路径压缩只发生在我们查询时经过的节点,没有途经的节点是不会被优化的。也就是说,随着查询次数增多,越来越多的路径会被优化,越到后面的查询越省力!论文证明,以上实现的合并与查询方法的均摊时间复杂度均为 O(1)。
下面给出两个版本的代码,第一个版本是简化版,数组下标就代表元素,即,你创建了大小为 4 的数组,那么就包含 0、1、2、3 这四个元素:
class UnionFind
{
private:
vector<int> parent;
vector<int> size;//size仅对代表节点有意义
public:
UnionFind(int n)
{
parent.resize(n);
size.resize(n, 0);
for (int i = 0; i < n; i++)
{
parent[i] = i; //初始状态下每个元素即为一个集合
size[i] = 1; //集合中只有自己
}
}
int find(int x)
{
//fix:如果没有x,仍然返回x
int anc = x;
int tmp;
while(anc != parent[anc])//先找到根节点
anc = parent[anc];
while(x != anc)//路径压缩
{
tmp = x;
x = parent[x];
parent[tmp] = anc;
}
return anc;
}
void unite(int x, int y)
{
int px = find(x);
int py = find(y);
if (px == py)
return;
if (size[px] < size[py])//按大小合并
{
parent[px] = py;
size[py] += size[px];
size[px] = 0;
}
else
{
parent[py] = px;
size[px] += size[py];
size[py] = 0;
}
}
bool isSameSet(int x, int y)
{
return find(x) == find(y);
}
};
第二个版本我们设置了接口,方便以后其他数据结构直接使用。我们需要先将元素串成链表,再传给 UnionFind 进行初始化。关于它的使用,参见最小生成树-K/P算法。
template<class T>
class UnionFind
{
unordered_map<T, T> parentMap;
unordered_map<T, int> sizeMap;
public:
UnionFind(const list<T> &nodeList);
T Find(T obj);
void Union(T obj1, T obj2);
bool isSameSet(T obj1, T obj2);
};
template<class T>
UnionFind<T>::UnionFind(const list<T> &nodeList)
{
for(auto n : nodeList)
{
parentMap.emplace(n, n);
sizeMap.emplace(n, 1);
}
}
template<class T>
T UnionFind<T>::Find(T obj)
{
if(parentMap.find(obj) == parentMap.end())
{
std::cout << "错误参数..." << std::endl;
exit(-1);
}
T anc = obj;
while(anc != parentMap[anc])
anc = parentMap[anc];
T tmp;
while(obj != anc)
{
tmp = parentMap[obj];
if(tmp != anc)
parentMap[obj] = anc;
obj = tmp;
}
return anc;
}
template<class T>
void UnionFind<T>::Union(T obj1, T obj2)
{
T obj1p = Find(obj1);
T obj2p = Find(obj2);
if(obj1 == obj2)
return;
if(sizeMap[obj1p] > sizeMap[obj2p])
{
parentMap[obj2p] = obj1p;
sizeMap[obj1p]++;
}
else
{
parentMap[obj1p] = obj2p;
sizeMap[obj2p]++;
}
}
template<class T>
bool UnionFind<T>::isSameSet(T obj1, T obj2)
{
if(Find(obj1) == Find(obj2))
return true;
else
return false;
}
本文结束。