
最小生成树-K/P算法
前言
简单而言,最小生成树就是:对于无向连通图而言,在不影响连通性的前提下,所得边的权值和最小的那棵树,如下图。
对于非连通无向图来说,它的每一连通分量同样有最小生成树,它们的并被称为最小生成森林。
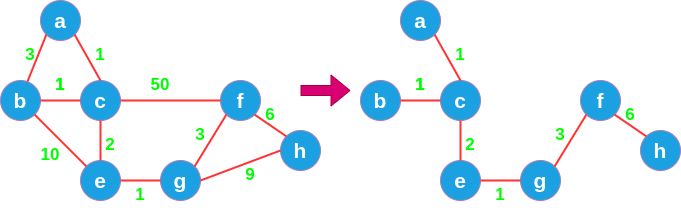
其意义显而易见。最小生成树广泛应用于日常生活中,比如在城镇间铺设电线,用最小生成树就能使成本最低;还比如网络路由等。
下面来看看两种著名的实现方式。
Kruskal算法
Kruskal 算法是对并查集的典型应用,其思想为贪心算法。
不熟悉并查集的朋友请先阅读初识并查集。
流程如下:
-
收集图中所有的边,并按权重生成小根堆。
也就是说,取边时按权重从小到大依次取出
-
从小根堆中弹出一条边,判断该边的两个端点是否属于同一个集合,如果不是,则该边入选,并合并两个端点;如果是,直接丢弃。
-
重复步骤 2 。
是不是感觉简单得有点反常?这就是贪心算法的优点,每一步优先选择最小边,最后的结果即为最小权值和;同时,并查集的使用也大大简化了算法。代码如下(头文件 graph):
#include<vector>
#include"../header/UnionFind.h"
#include"../header/graph.h"
#include<queue>
using std::priority_queue;
using std::vector;
struct cmp
{
bool operator()(graphEdge* a, graphEdge* b)
return a->weight > b->weight;
};
unordered_set<graphEdge*> kruskal(const graph &_graph)
{
unordered_set<graphEdge*> ret;
list<graphNode*> listNode;
for(auto n : _graph.nodes)
listNode.push_back(n.second);
UnionFind<graphNode*> uf(listNode); //初始化并查集
priority_queue<graphEdge*, vector<graphEdge*>, cmp> queEdge; //自定义结构必须传入比较器cmp
for(auto n : _graph.edges) //收集图中所有的边
queEdge.push(n);
graphEdge* tmp;
while(!queEdge.empty())
{
tmp = queEdge.top();
queEdge.pop();
if(!uf.isSameSet(tmp->to, tmp->from)) //如果两端点不属于同一个集合,则
{
ret.emplace(tmp); //添加此边
uf.Union(tmp->from, tmp->to); //合并两点
}
}
return ret;
}
Prim算法
Prim 算法的思想仍然是贪心算法。个人感觉 Prim 的整个流程似乎是广度优先遍历,是在黑暗之中不停探路的过程。为什么说是像在探路?看看下面的流程便知。
-
假设初始状态下,所有的洞穴(节点)和通道(边)都在黑暗中不可见。
-
我随机来到 a 洞穴,手中的火把将 a 洞穴和相连的通道照亮(变为绿色)。
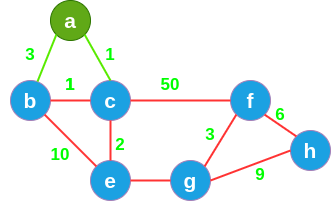
-
在未标记过的绿色通道中选择最短的通道,并将其标记,因此来到 c 洞穴, c 洞穴以及相连的通道都被照亮。
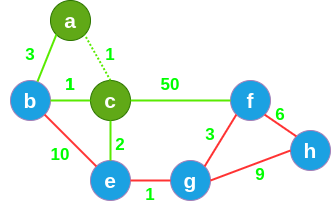
-
继续,在未标记过的绿色通道中选择最短的通道,并将其标记,因此来到 b 洞穴, b 洞穴以及相连的通道都被照亮。
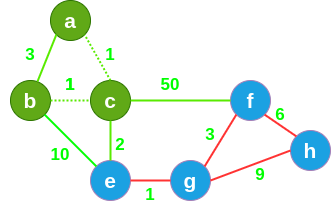
-
继续,在未标记过的绿色通道中选择最短的通道,并将其标记,因此来到 e 洞穴, e 洞穴以及相连的通道都被照亮。
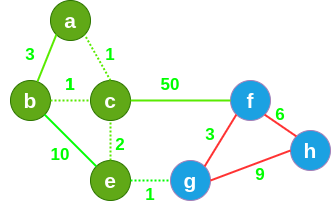
-
重复以上过程,最后得到最小生成树如下:
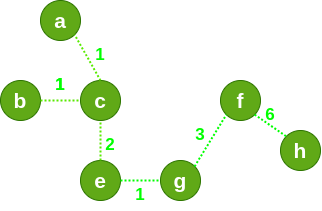
代码如下:
#include"../header/graph.h"
#include<iostream>
#include<queue>
#include<list>
#include<unordered_set>
using std::priority_queue;
using std::list;
using std::unordered_set;
struct cmp
{
bool operator()(graphEdge* a, graphEdge* b)
return a->weight > b->weight;
};
list<graphEdge*> prim(graph _graph)
{
unordered_set<graphNode*> unlockedNodes; //解锁(绿色)的洞穴
priority_queue<graphEdge*, vector<graphEdge*>, cmp> unlockedEdges;//解锁(绿色)的路径
list<graphEdge*> ret;
graphNode* node;
graphEdge* edge;
for(auto n : _graph.nodes)
{
node = n.second;
if(unlockedNodes.find(node) != unlockedNodes.end())//如果此洞穴已经访问过,则不再来
continue;
unlockedNodes.emplace(node);//将洞穴点亮
for(auto e : node->edges)
unlockedEdges.push(e);//将洞穴所连的通道点亮
while(!unlockedEdges.empty())
{
edge = unlockedEdges.top();//选择最短的通道
unlockedEdges.pop();
if(unlockedNodes.find(edge->to) == unlockedNodes.end())//如果另一端的洞穴已经到访过,则不再去
{
unlockedNodes.emplace(edge->to);//到访新洞穴,点亮
ret.push_back(edge);//标记
for(auto e : edge->to->edges)//将该洞穴所连通道也都点亮
unlockedEdges.push(e);
}
}
}
return ret;
}
注意,这里最外层的 for 循环是为了防止非连通图,即森林:
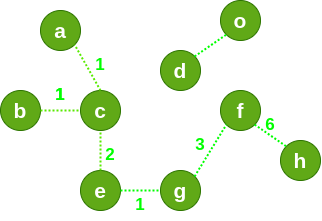
所以必须从每个节点都开始访问一遍,才能遍历所有的连通分量。
测试:
int main()
{
//我们的graph是有向图,最小生成树要求无向图,所以要求x->y,同时y->x
vector<vector<int>> vec = {
{3, 'a', 'b'},
{3, 'b', 'a'},
{1, 'a', 'c'},
{1, 'c', 'a'},
{1, 'b', 'c'},
{1, 'c', 'b'},
{10, 'b', 'e'},
{10, 'e', 'b'},
{2, 'c', 'e'},
{2, 'e', 'c'},
{50, 'c', 'f'},
{50, 'f', 'c'},
{1, 'e', 'g'},
{1, 'g', 'e'},
{6, 'f', 'h'},
{6, 'h', 'f'},
{3, 'f', 'g'},
{3, 'g', 'f'},
{9, 'g', 'h'},
{9, 'h', 'g'}
};
graph gra = graphAdaptor(vec);
auto ret = kruskal(gra);
for(auto e : ret)
std::cout << e->weight << std::endl;
auto ret1 = prim(gra);
for(auto e : ret1)
std::cout << e->weight << std::endl;
}
本文结束。