
实现用户进程-代码详解
本文前置内容:实现用户进程-进入用户态
本节对应分支:userprog
初始化TSS、C语言接管GDT
下面是 global.h 中添加的代码:
//文件说明:global.h
//=============用户进程的段选择子================
#define SELECTOR_U_CODE ((5 << 3) + (TI_GDT << 2) + RPL3)
#define SELECTOR_U_DATA ((6 << 3) + (TI_GDT << 2) + RPL3)
#define SELECTOR_U_STACK SELECTOR_U_DATA
// ===============GDT描述符属性=================
#define DESC_G_4K 1
#define DESC_D_32 1
#define DESC_L 0 // 64位代码标记,此处标记为0便可。
#define DESC_AVL 0 // cpu不用此位,暂置为0
#define DESC_P 1
#define DESC_DPL_0 0
#define DESC_DPL_1 1
#define DESC_DPL_2 2
#define DESC_DPL_3 3
#define DESC_S_CODE 1 // s为1时表示存储段
#define DESC_S_DATA DESC_S_CODE
#define DESC_S_SYS 0 // s为0时表示系统段.
#define DESC_TYPE_CODE 8 // x=1,c=0,r=0,a=0 代码段是可执行的,非依从的,不可读的,已访问位a清0.
#define DESC_TYPE_DATA 2 // x=0,e=0,w=1,a=0 数据段是不可执行的,向上扩展的,可写的,已访问位a清0.
#define DESC_TYPE_TSS 9 // B位为0,不忙
#define GDT_ATTR_HIGH ((DESC_G_4K << 7) + (DESC_D_32 << 6) + (DESC_L << 5) + (DESC_AVL << 4))
#define GDT_CODE_ATTR_LOW_DPL3 ((DESC_P << 7) + (DESC_DPL_3 << 5) + (DESC_S_CODE << 4) + DESC_TYPE_CODE)
#define GDT_DATA_ATTR_LOW_DPL3 ((DESC_P << 7) + (DESC_DPL_3 << 5) + (DESC_S_DATA << 4) + DESC_TYPE_DATA)
//================ TSS描述符属性===================
#define TSS_DESC_D 0
#define TSS_ATTR_HIGH ((DESC_G_4K << 7) + (TSS_DESC_D << 6) + (DESC_L << 5) + (DESC_AVL << 4) + 0x0)
#define TSS_ATTR_LOW ((DESC_P << 7) + (DESC_DPL_0 << 5) + (DESC_S_SYS << 4) + DESC_TYPE_TSS)
#define SELECTOR_TSS ((4 << 3) + (TI_GDT << 2 ) + RPL0)
//================ GDT描述符 =====================
struct gdt_desc
{
uint16_t limit_low_word;
uint16_t base_low_word;
uint8_t base_mid_byte;
uint8_t attr_low_byte;
uint8_t limit_high_attr_high;
uint8_t base_high_byte;
};
- 第 3~5 行定义了用户进程的段选择子,其中代码段选择子索引为 5,即用户代码段的描述符位于 GDT 的第 5 号描述符的位置处;数据段和栈段共享一个描述符,选择子索引为 6 。你可能会疑惑,为什么只定义了一套用户的选择子,万一将来有多个用户进程同时运行,这几个选择子岂不是不够用?实际上只需要一套用户选择子就可以了,因为所有用户进程都共享这一套选择子 。为什么可以共享呢?这便体现出虚拟空间下平坦模型的优越性了。因为每个进程都有自己独立的虚拟地址空间,平坦模型下数据段和代码段描述符的基址直接设为 0,所以执行流只取决于 EIP 而依赖 CS。反观分段模型,由于没有虚拟地址空间,各个用户进程被分配到不同区域的物理内存中,所以为了隔离它们,每个用户进程的段基址都不相同,因此需要为每个用户进程都分配一套段选择子和段描述符 ,不仅管理繁琐,而且效率低下。
另外,当初咋们在loader.s中设计 GDT 表时,并没有为用户和 TSS 预留段描述符,所以现在必须在loader.s中加上一行代码以预留空间:
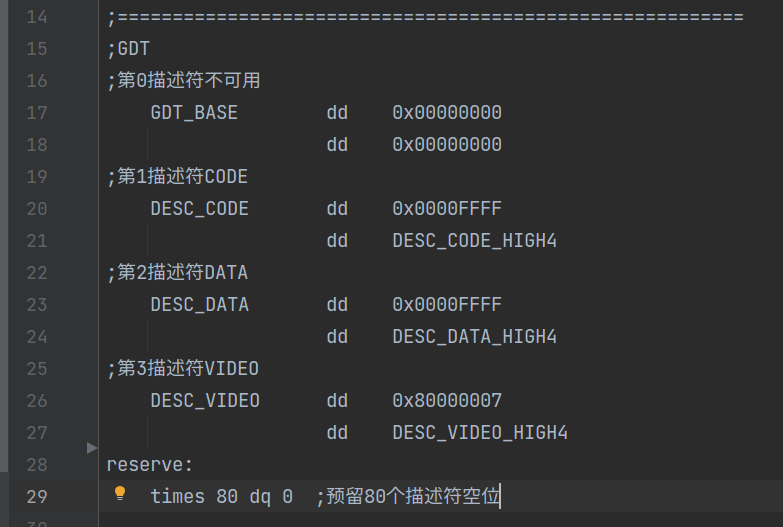
- 之前是在
loader.s中直接书写 GDT ,为了方便,现在我们使用 C 语言接管 GDT,以方便在 GDT 中添加和修改段描述符。所以在头文件中定义了段描述符和 TSS 描述符的各个属性以及段描述符的结构体gdt_struct。关于各个位的解释,参见GDT 。
下面是 tss.c :
static struct xdt_ptr gdt_operand;
static uint16_t tss_slt;
/* 任务状态段tss结构 */
struct tss
{
uint32_t backlink;
uint32_t* esp0;
uint32_t ss0;
uint32_t* esp1;
uint32_t ss1;
uint32_t* esp2;
uint32_t ss2;
uint32_t cr3;
uint32_t (*eip) (void);
uint32_t eflags;
uint32_t eax;
uint32_t ecx;
uint32_t edx;
uint32_t ebx;
uint32_t esp;
uint32_t ebp;
uint32_t esi;
uint32_t edi;
uint32_t es;
uint32_t cs;
uint32_t ss;
uint32_t ds;
uint32_t fs;
uint32_t gs;
uint32_t ldt;
uint32_t trace;
uint32_t io_base;
};
static struct tss tss;
/* 更新tss中esp0字段的值为pthread的0级线 */
void update_tss_esp(struct task_struct* pthread)
{
tss.esp0 = (uint32_t*)((uint32_t)pthread + PG_SIZE);
}
/* 创建gdt描述符 */
static struct gdt_desc make_gdt_desc(uint32_t* desc_addr, uint32_t limit, uint8_t attr_low, uint8_t attr_high)
{
uint32_t desc_base = (uint32_t)desc_addr;
struct gdt_desc desc;
desc.limit_low_word = limit & 0x0000ffff;
desc.base_low_word = desc_base & 0x0000ffff;
desc.base_mid_byte = ((desc_base & 0x00ff0000) >> 16);
desc.attr_low_byte = (uint8_t)(attr_low);
desc.limit_high_attr_high = (((limit & 0x000f0000) >> 16) + (uint8_t)(attr_high));
desc.base_high_byte = desc_base >> 24;
return desc;
}
/* 在gdt中创建tss并重新加载gdt */
void tss_init()
{
put_str("tss_init start\n",DEFUALT);
uint32_t tss_size = sizeof(tss);
memset(&tss, 0, tss_size);
tss.ss0 = SELECTOR_K_STACK;
tss.io_base = tss_size;
/* gdt基址为0x910,把tss放到第4个位置,也就是0x910+0x20的位置 */
/* 在gdt中添加dpl为0的TSS描述符 */
*((struct gdt_desc*)0xc0000930) = make_gdt_desc((uint32_t*)&tss, tss_size - 1, TSS_ATTR_LOW, TSS_ATTR_HIGH);
/* 在gdt中添加dpl为3的数据段和代码段描述符 */
*((struct gdt_desc*)0xc0000938) = make_gdt_desc((uint32_t*)0, 0xfffff, GDT_CODE_ATTR_LOW_DPL3, GDT_ATTR_HIGH);
*((struct gdt_desc*)0xc0000940) = make_gdt_desc((uint32_t*)0, 0xfffff, GDT_DATA_ATTR_LOW_DPL3, GDT_ATTR_HIGH);
/* gdt 16位的limit 32位的段基址 */
load_xdt(&gdt_operand,8 * 7 - 1,0xc0000910);
tss_slt = SELECTOR_TSS;
asm volatile ("lgdt gdt_operand");
asm volatile ("ltr tss_slt");
put_str("tss_init and ltr done\n",DEFUALT);
}
- 第 4~33 行定义了 TSS 结构,这没有太多要说的,有个小问题是,结构体定义不应该放在头文件中吗,这里为什么要放在 C 文件中呢?是不是不太规范?这也是笔者之前的误解,原以为只要是宏定义或者结构体定义一类的都应该放在头文件,而 C 文件中只放函数定义,这样才显得规范。实际上并不是如此,原则应该是:如果其可见性超出一个 .c 文件,那么应当放入 .h 中,如果只是某一个 .c 里需要这么一个结构作为辅助,直接放入这个.c中更好一些 。放在 .c 还是 .h 取决于该结构是否要暴露给其他 .c,能放 .c 绝不放 .h 。而 TSS 结构只会在此文件中使用,所以就定义在此 .c 文件中。
- 第 37 行,update_tss_esp() 用来将 TSS 中 esp0 字段的值更新为 pthread 的内核线。如上节内容所说,所有任务共享一个 TSS,只是在任务切换时更新 ESP0 的值。
- 第 61 行,将 TSS 的 io_base 字段设置为 TSS 的大小,这表示此 TSS 中没有 IO 位图。
- 第 62 行,GDT 的基址为 0x910,这是如何确定的?见下面
loader.s的片段即可知道。
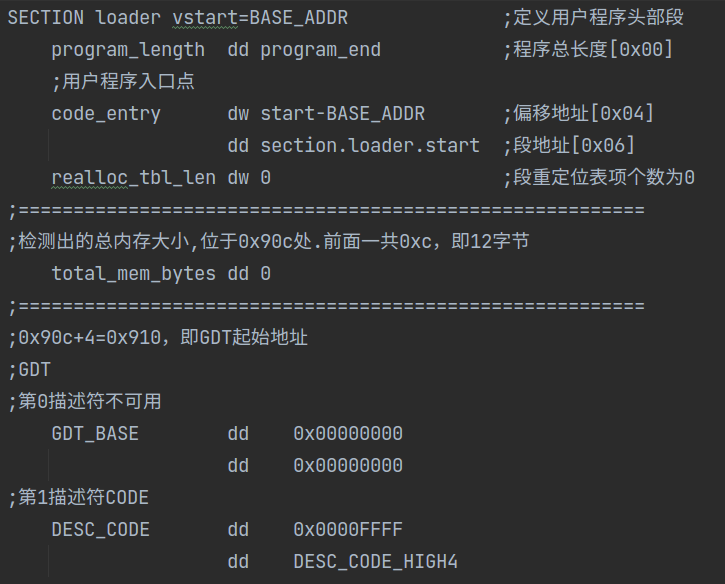
- 第 69 行的 load_xdt 函数,咋们之前用它设置过 IDTR,定义在 global.h 中。gdt_operand 是加载 GDT 时用的操作数,设置好 gdt_operand 的基址和界限后,第 71 行便使用内联汇编
lgdt指令加载 GDTR。至于为什么要将 gdt_operand 和 tss_slt 定义为全局静态变量,这在之前的文章中反复提及过,不再赘述。同理,第 72 行使用ltr指令将 TSS 的选择子 tss_slt 加载进 TR 寄存器,由于 TSS 只有一个,所以只会加载这一次,以后就不会再修改 TR 了。
用户进程的虚拟地址空间
在内存管理-基础篇中,我们划出了三个内存池:内核物理内存池、内核虚拟内存池、用户物理内存池。为了实现用户进程的虚拟地址空间,我们还需要给每个进程设置私有的用户虚拟内存池。见以下步骤。
在task_struct中添加虚拟内存池
//文件说明:thread.h
struct task_struct
{
uint32_t* self_kstack; // 各内核线程都用自己的内核栈
enum task_status status;
char name[16];
uint8_t priority;
uint8_t ticks; // 每次在处理器上执行的时间嘀嗒数
uint32_t elapsed_ticks; // 此任务自上cpu运行后至今占用了多少cpu嘀嗒数
struct list_elem general_tag; // general_tag的作用是用于线程在一般队列中的结点
struct list_elem all_list_tag;// all_list_tag的作用是用于线程队列thread_all_list中的结点
uint32_t* pgdir; // 进程页表
uint32_t stack_magic; // 用这串数字做栈的边界标记,用于检测栈的溢出
struct virtual_addr userprog_vaddr; // 用户进程的虚拟地址池
};
第 14 行即为用户进程的虚拟内存池。
用户虚拟内存管理
在 内存管理-进阶中,我们留下了部分内容等到实现用户进程时补充,如下:
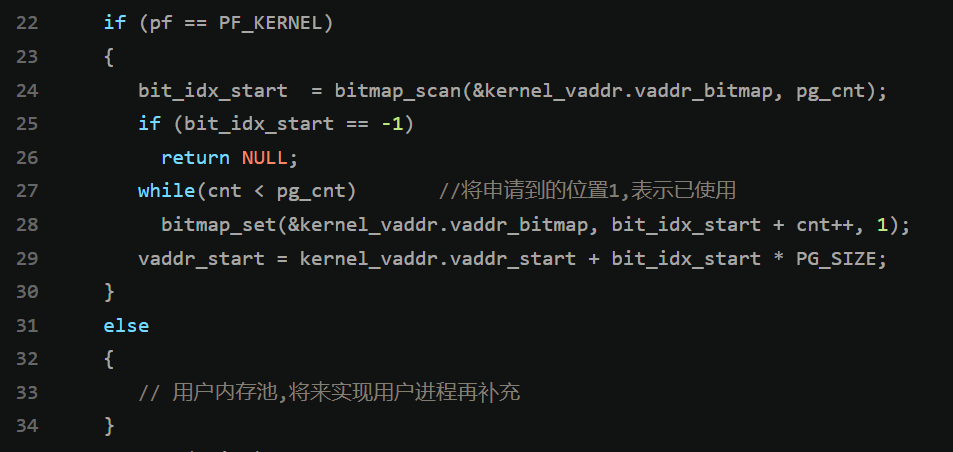
第 33 行的作用和其上内核部分的代码相似,都是在申请虚拟内存。以下代码补齐这部分内容:
//文件说明:memory.c
//....
else
{
// 用户内存池
struct task_struct* cur = running_thread();
bit_idx_start = bitmap_scan(&cur->userprog_vaddr.vaddr_bitmap, pg_cnt);
if (bit_idx_start == -1)
return NULL;
while(cnt < pg_cnt)
bitmap_set(&cur->userprog_vaddr.vaddr_bitmap, bit_idx_start + cnt++, 1);
vaddr_start = cur->userprog_vaddr.vaddr_start + bit_idx_start * PG_SIZE;
/*0xc0000000-PAGE_SIZE作为3级用户栈已经在start_process中被分配*/
assert((uint32_t)vaddr_start < (0xc0000000 - PG_SIZE));
}
//....
逻辑清晰,不再解释。另外还添加了几个必要的内存管理函数:
//文件说明:memory.c
/* 在用户空间中申请4k内存,并返回其虚拟地址 */
void* get_user_pages(uint32_t pg_cnt)
{
lock_acquire(&user_pool.lock);
void* vaddr = malloc_page(PF_USER, pg_cnt);
memset(vaddr, 0, pg_cnt * PG_SIZE);
lock_release(&user_pool.lock);
return vaddr;
}
/* 将地址vaddr与pf池中的物理地址关联,仅支持一页空间分配 */
void* get_a_page(enum pool_flags pf, uint32_t vaddr)
{
struct pool* mem_pool = pf & PF_KERNEL ? &kernel_pool : &user_pool;
lock_acquire(&mem_pool->lock);
struct task_struct* cur = running_thread();
int32_t bit_idx = -1;
/* 若当前是用户进程申请用户内存,就修改用户进程自己的虚拟地址位图 */
if (cur->pgdir != NULL && pf == PF_USER)
{
bit_idx = (vaddr - cur->userprog_vaddr.vaddr_start) / PG_SIZE;
assert(bit_idx > 0);
bitmap_set(&cur->userprog_vaddr.vaddr_bitmap, bit_idx, 1);
}
else if (cur->pgdir == NULL && pf == PF_KERNEL)
{
/* 如果是内核线程申请内核内存,就修改kernel_vaddr. */
bit_idx = (vaddr - kernel_vaddr.vaddr_start) / PG_SIZE;
assert(bit_idx > 0);
bitmap_set(&kernel_vaddr.vaddr_bitmap, bit_idx, 1);
}
else
panic("get_a_page:not allow kernel alloc userspace or user alloc kernelspace by get_a_page",__FILE__,__LINE__,__func__);
void* page_phyaddr = palloc(mem_pool);
if (page_phyaddr == NULL)
return NULL;
page_table_add((void*)vaddr, page_phyaddr);
lock_release(&mem_pool->lock);
return (void*)vaddr;
}
/* 得到虚拟地址映射到的物理地址 */
uint32_t addr_v2p(uint32_t vaddr)
{
uint32_t* pte = pte_ptr(vaddr);
/* (*pte)的值是页表所在的物理页框地址,
* 去掉其低12位的页表项属性+虚拟地址vaddr的低12位 */
return ((*pte & 0xfffff000) + (vaddr & 0x00000fff));
}
-
get_user_pages 和 get_kernel_page 的逻辑完全相同,不再赘述。提一下,笔者在内存管理-进阶中提到过如下内容:
扫描和设置位图必须连续,中间不能切换线程 。这里和线程切换有关,简单解释:比如当线程 A 执行完第 58 行,成功找到一个物理页面;紧接着,切换到 B 线程,恰好 B 线程也执行到了 58 行,也成功找到了一个物理页面。由于线程 A 找到后还没来得及将该位置 1 就被换下 CPU,因此 A、B 这两个线程此时申请的是同一个物理页面!这必然会引发问题 。因此扫描和设置位图必须保证原子操作。需要注意的是,此处代码并没有保证原子性,未来我们会用锁来实现 。当然,如果读者实在不放心,可以先在此函数首尾分别关开中断,避免时钟中断引发任务调度。
现在咋们已经实现了锁机制,所以这里申请内存时用锁来保证原子性。锁加在 pool 结构体中:
struct pool //管理物理内存 { struct bitmap pool_bitmap; // 本内存池用到的位图结构,用于管理物理内存 uint32_t phy_addr_start; // 本内存池所管理物理内存的起始地址 uint32_t pool_size; // 本内存池字节容量 struct lock lock; // 保证内存申请时的原子操作 }; -
第 13 行定义 get_a_page 函数,该函数与 get_kernel_page 或 get_user_page 的差别在于前者能够申请指定位置的虚拟内存,而后者则无法指定位置。该函数待会用来指定在 0xc0000000 处申请一页虚拟内存作用户栈。
-
addr_v2p 函数,其中 2 和 to 同音,即 addr_v_to_p,功能是将虚拟地址 vaddr 转换为对应的物理地址。下面咋们马上就会用到此函数。
创建用户进程
这部分内容很多,打起精神啦!
在中断栈中构建用户进程的上下文时,需要设置 eflags 寄存器,所以在 global 中定义好 eflags 的属性位:
//文件说明:global.h
//...
#define EFLAGS_MBS (1 << 1) // 该位保留,总是为1
#define EFLAGS_IF_1 (1 << 9) // if为1,开中断
#define EFLAGS_IF_0 0 // if为0,关中断
#define EFLAGS_IOPL_3 (3 << 12) // IOPL3,用于测试用户程序在非系统调用下进行IO
#define EFLAGS_IOPL_0 (0 << 12) // IOPL0
#define DIV_ROUND_UP(X, STEP) ((X + STEP - 1) / (STEP)) //用于除法的向上取整,如2/3=1
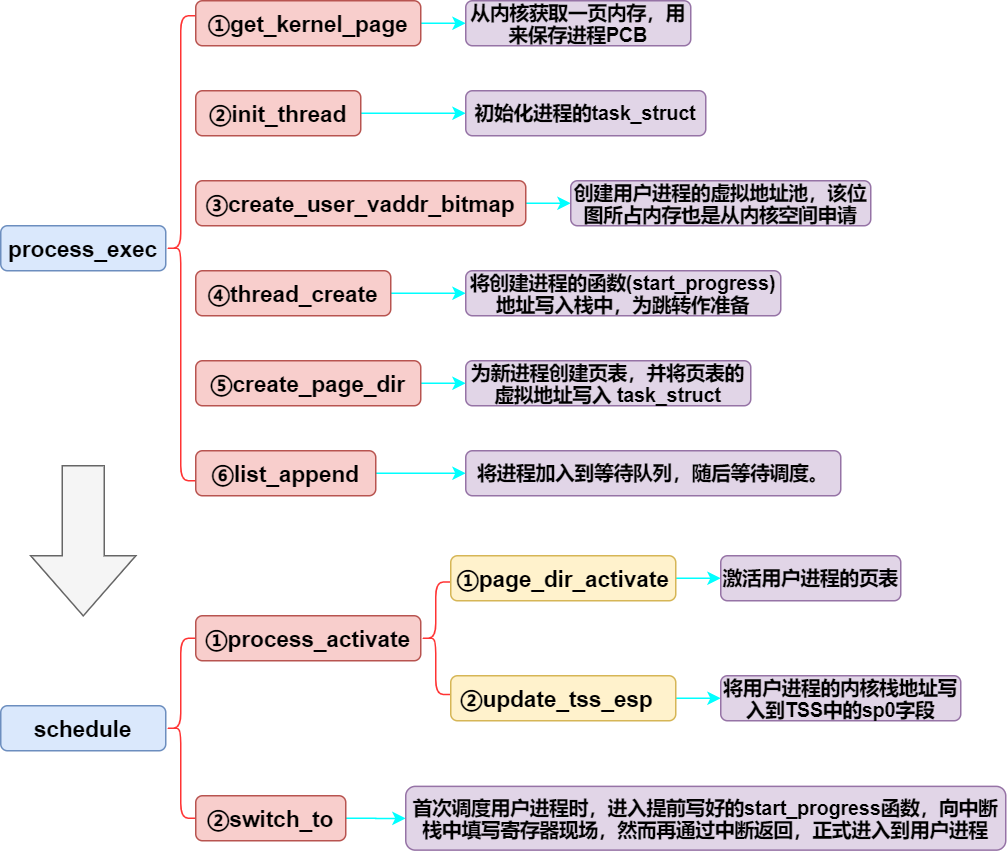
下面则开始创建用户进程,注意上节中的进程创建流程图对比 :
//文件说明:process.c
extern struct list thread_ready_list;
extern struct list thread_all_list;
static struct intr_stack* proc_stack;
static uint32_t pagedir_phy_addr;
void intr_exit();
void start_process(void* filename_)
{
void* function = filename_;
struct task_struct* cur = running_thread();
cur->self_kstack += sizeof(struct thread_stack); //跨过thread_stack,指向intr_stack
proc_stack = (struct intr_stack*)cur->self_kstack; //可以不用定义成结构体指针
proc_stack->edi = proc_stack->esi = proc_stack->ebp = proc_stack->esp_dummy = 0;
proc_stack->ebx = proc_stack->edx = proc_stack->ecx = proc_stack->eax = 0;
proc_stack->gs = 0; // 不允许用户态直接访问显存资源,用户态用不上,直接初始为0
proc_stack->ds = proc_stack->es = proc_stack->fs = SELECTOR_U_DATA;
proc_stack->eip = function; // 待执行的用户程序地址
proc_stack->cs = SELECTOR_U_CODE;
proc_stack->eflags = (EFLAGS_IOPL_0 | EFLAGS_MBS | EFLAGS_IF_1);
proc_stack->esp = (void*)((uint32_t)get_a_page(PF_USER, USER_STACK3_VADDR) + PG_SIZE) ;
proc_stack->ss = SELECTOR_U_DATA;
asm volatile("mov esp,proc_stack");
asm volatile("jmp intr_exit");
}
/* 击活页表 */
void page_dir_activate(struct task_struct* p_thread)
{
/********************************************************
* 执行此函数时,当前任务可能是线程。
* 之所以对线程也要重新安装页表, 原因是上一次被调度的可能是进程,
* 否则不恢复页表的话,线程就会使用进程的页表了。
********************************************************/
/* 若为内核线程,需要重新填充页表为0x100000 */
pagedir_phy_addr = 0x100000; // 默认为内核的页目录物理地址,也就是内核线程所用的页目录表
if (p_thread->pgdir != NULL) // 用户态进程有自己的页目录表
pagedir_phy_addr = addr_v2p((uint32_t)p_thread->pgdir);
/* 更新页目录寄存器cr3,使新页表生效 */
asm volatile ("mov eax,pagedir_phy_addr");
asm volatile ("mov cr3,eax");
}
/* 激活线程或进程的页表,更新tss中的esp0为进程的特权级0的栈 */
void process_activate(struct task_struct* p_thread)
{
assert(p_thread != NULL);
/* 激活该进程或线程的页表 */
page_dir_activate(p_thread);
/* 内核线程特权级本身就是0特权级,处理器进入中断时并不会从tss中获取0特权级栈地址,故不需要更新esp0 */
if (p_thread->pgdir)
/* 更新该进程的esp0*/
update_tss_esp(p_thread);
}
/* 创建页目录表,将当前页表的表示内核空间的pde复制,
* 成功则返回页目录的虚拟地址,否则返回-1 */
uint32_t* create_page_dir(void)
{
/* 用户进程的页目录表不能让用户直接访问到,所以在内核空间来申请 */
uint32_t* page_dir_vaddr = get_kernel_pages(1);
if (page_dir_vaddr == NULL)
{
console_put_str("create_page_dir: get_kernel_page failed!",FT_RED);
return NULL;
}
/************************** 1 先复制页表 *************************************/
/* page_dir_vaddr + 0x300*4 是内核页目录的第768项 */
memcpy((uint32_t*)((uint32_t)page_dir_vaddr + 0x300*4), (uint32_t*)(0xfffff000+0x300*4), 1024);
/************************** 2 更新页目录地址 **********************************/
uint32_t new_page_dir_phy_addr = addr_v2p((uint32_t)page_dir_vaddr);
/* 页目录地址是存入在页目录的最后一项,更新页目录地址为新页目录的物理地址 */
page_dir_vaddr[1023] = new_page_dir_phy_addr | PG_US_U | PG_RW_W | PG_P_1;
return page_dir_vaddr;
}
/* 创建用户进程虚拟地址位图 */
void create_user_vaddr_bitmap(struct task_struct* user_prog)
{
user_prog->userprog_vaddr.vaddr_start = USER_VADDR_START;
uint32_t bitmap_pg_cnt = DIV_ROUND_UP((0xc0000000 - USER_VADDR_START) / PG_SIZE / 8 , PG_SIZE);
user_prog->userprog_vaddr.vaddr_bitmap.bits = get_kernel_pages(bitmap_pg_cnt);
user_prog->userprog_vaddr.vaddr_bitmap.btmp_bytes_len = (0xc0000000 - USER_VADDR_START) / PG_SIZE / 8;
bitmap_init(&user_prog->userprog_vaddr.vaddr_bitmap);
}
/* 创建用户进程 */
void process_execute(void* filename, char* name)
{
/** pcb内核的数据结构,由内核来维护进程信息,因此要在内核内存池中申请 **/
struct task_struct* thread = get_kernel_pages(1);
init_thread(thread, name, DEFUALT_PRIO);
create_user_vaddr_bitmap(thread);
thread_create(thread, start_process, filename);//start_process(filename)
thread->pgdir = create_page_dir();
enum intr_status old_status = intr_disable();
assert(!elem_find(&thread_ready_list, &thread->general_tag));
list_append(&thread_ready_list, &thread->general_tag);
assert(!elem_find(&thread_all_list, &thread->all_list_tag));
list_append(&thread_all_list, &thread->all_list_tag);
intr_set_status(old_status);
}
-
start_process 中,proc_stack 结构体指向中断栈,并初始化进程上下文。
-
第 9 行,需要说明的是,用户进程一般是硬盘中的一段程序,需要加载到内存,然后再运行,所以进程的定义就是“运行中的程序”。但目前我们还没有实现硬盘驱动程序和文件系统,所以用户进程只能由一个函数代替 ,实际上,这两者也没有本质区别。
-
第 15 行,由于 用户不能直接使用显存,所以将 gs 直接初始化为 0,则用户使用该选择子时,会索引到 GDT 的第 0 号描述符而引发异常。
-
第 20 行,调用 get_a_page() 在指定位置,即用户空间 3GB 顶端处申请一页内存用来作用户栈,这在之前有所提及。
用户栈只有一页吗?笔者暂不清楚当栈使用超过一页会发生什么,后续补充。
-
第 23 行,intr_exit 是从
interrupt.s引入的函数,专门处理中断返回。这没有什么好说的,只是为了复用代码,也可以直接在 23 行处使用内联汇编连续弹栈并iret。iret后执行流就转移到用户进程啦! -
第 27 行,page_dir_active,页表激活函数。从流程图中可以看见,该函数在 schedule() 中被调用,如下:
//文件说明:thread.c //...... struct task_struct* next = elem2entry(struct task_struct, general_tag, thread_tag); next->status = TASK_RUNNING; process_activate(next); switch_to(cur, next); }可见,每当任务切换(swtich_to)前,都会重新激活页表 ,这不禁引发我们的疑惑:不是进程才有独立的地址空间吗?怎么连线程都要激活页表了呢?其实这可以在上节进程的实现方式找到答案。在 Linux 中,多个地址空间相同的线程组成了一个进程 ,所以线程也需要记录页表。需要注意的是,目前我们只实现了内核线程(thread_start) 和用户进程 (process_execute),还未实现用户线程 (未来看情况按需添加),所以 task_struct 中的 pgdir 只分为两种情况:NULL 和其他值;如果为 NULL,则说明该任务为内核线程;如果为非 NULL,则说明该任务为用户进程。
另外,第 40 行加载 cr3 有大坑! 还记得吗,在加载内核一文中,笔者将内核的起始虚拟地址设置为了 0x1500,并提醒读者未来这个 0x1500 会留下问题。这个问题就在此处浮现:首次切换页表之前,执行流一直位于内核进程中,而内核进程虚拟空间的低 1MB 和高 3GB 处都是内核(这在开启分页-代码详解中早有说明,忘记的读者请回头复习)。又因为之前将内核的起始虚拟地址设置为了 0x1500,所以一直以来内核始终运行在低端 1MB 处,而非高 3GB 处。关键来了,当内核执行流运行到第 40 行切换页表时,切换前执行流位于 1MB 下,切换后当然也仍位于 1MB 下(因为代码中的地址都是提前编译好的),但是,切换到用户进程的页表后,低端 1MB 就不再是内核啦(对于用户进程而言,内核只位于高 3GB 处)之前说过,用户进程的低端 128MB 为保留,没有任何东西,所以执行流运行在用户进程虚拟空间的低端 1MB 下将必定出错!因此,为了保证切换页表前后执行流能够统一,我们必须将内核的起始虚拟地址设置为 0xc0001500,这样对于内核进程和用户进程来说,内核都运行在高 3GB 上,切换页表前后执行流就不会改变。修改如下:#文件说明:makefile $(BUILD)/kernel.bin: $(KERNEL) ld -m elf_i386 $^ -o $@ -Ttext 0xc0001500这里也是卡了笔者很久,如果当初不作死修改 Ttext,也不会引发这些问题,但实际上,不就是这些找 Bug 的过程加深了我们对程序的理解吗?
-
第 51 行,只有用户进程才会更新 TSS 中的 ESP0,因为从内核进入中断不涉及特权级转移,从用户进程进入中断才会切换到对应的内核栈。
-
第 58 行是笔者期待已久的页表创建函数 create_page_dir(),该函数为用户进程创建对应的页目录表,其任务很简单:1)申请一页内存用来存放页目录表 ;2)将内核页目录的第 768~1022 项复制到用户页目录表的相同位置,从而实现所有用户进程共享内核 (这在开启分页-代码详解中重点提到过);3)将用户进程页目录表的物理地址写入第 1023 号页目录项,这是为了访问页目录表和页表本身,详细原因仍请参考开启分页-代码详解。注意,用户进程的页目录表和页表不能安装在用户空间中,而是安装在内核空间里 ,否则用户就可能自己修改页表,映射任意的内存地址,访问任何内存,进程间、内核的隔离保护就失去了意义。
另外,不知道读者是否和我一样有这样的疑惑:为什么没有为用户程序本身开辟页表?也就是说,现在只映射了 3~4GB 的内核,而没有映射 0~3GB 的用户空间,那用户程序本身运行在哪?笔者从两个方面来解释此问题:
1)由于现在还没有完成硬盘驱动和文件系统,所以只能使用函数(如下面的u_prog_a、u_prog_b)来代替用户程序。而这些函数也是同样定义在 main.c 中,所以它们都会被链接进 kernel.bin,然后载入内核。换句话说,这些函数虽然是用户进程,但也位于 3~4GB 空间中(即使位于内核空间,特权级仍然为 3)。这只是目前为了演示用户进程而作的妥协 。
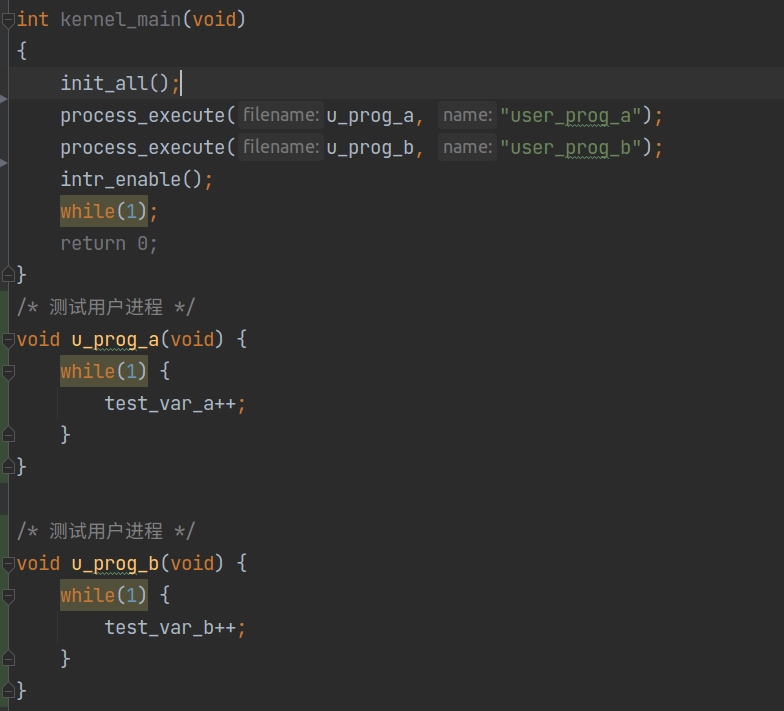
2)真正的用户进程加载是从硬盘读取程序并载入内存,进而运行,大致流程是这样的:
{% mermaid %}
graph LR
A{创建独立的虚拟空间}–>B{读取可执行文件头}–>C{建立虚拟空间和可执行文件的映射关系}–>D{将EIP设置为可执行文件的入口地址,开始运行}
{% endmermaid %}
啊啥?这不是还没将程序加载进内存吗?怎么就开始运行啦?是这样的,比如入口地址为0x08048000,当执行流运行到该地址时,发现页面0x08048000~0x08049000是空页面,于是陷入缺页异常,异常处理程序通过第三步建立的映射关系找到可执行文件中缺失页面对应的部分代码,然后再将该部分载入内存,最后重新运行 。相关详细内容可参考《链接、装载与库》。
综上两点考虑,当前无需建立其他部分的映射。 -
第 78 行,create_user_vaddr_bitmap() 函数用来为用户进程创建虚拟内存池,以便管理内存空间。其中 USER_VADDR_START 的值即为
0x08048000。该函数逻辑清晰,不做说明。 -
第 88 行便是 process_execute() 函数。需要说明的是,该函数是在内核中被调用来创建用户进程的,而 fork 函数则是在用户程序中来创建子进程的,两者有巨大区别,将来实现 fork 时还会提到这一点。
大功告成,了解了具体实现后,再来回顾进程创建的整个过程,思路也许会变得更清晰:
运行用户进程
//文件说明:main.c
void k_thread_a(void*);
void k_thread_b(void*);
void u_prog_a(void);
void u_prog_b(void);
int test_var_a = 0, test_var_b = 0;
int kernel_main(void)
{
init_all();
thread_start("k_thread_a", 31, k_thread_a, "argA ");
thread_start("k_thread_b", 31, k_thread_b, "argB ");
process_execute(u_prog_a, "user_prog_a");
process_execute(u_prog_b, "user_prog_b");
intr_enable();
while(1);
return 0;
}
/* 测试用户进程 */
void u_prog_a(void) {
while(1) {
test_var_a++;
}
}
/* 测试用户进程 */
void u_prog_b(void) {
while(1) {
test_var_b++;
}
}
/* 在线程中运行的函数 */
void k_thread_a(void* arg)
{
char* para = arg;
while(1)
{
console_put_int(test_var_a,FT_RED,HEX);
}
}
/* 在线程中运行的函数 */
void k_thread_b(void* arg) {
char* para = arg;
while(1) {
console_put_int(test_var_b,FT_YELLOW,HEX);
}
}
然而运行结果不尽人意:{%
dplayer
“url=/2022/video/userpro.mp4”
“pic=/2022/image/1.jpg” //设置封面图,同样是放在根目录下面
“loop=false” //循环播放
“theme=#FADFA3” //主题
“autoplay=false” //自动播放
“screenshot=true” //允许截屏
“hotkey=true” //允许hotKey,比如点击空格暂停视频等操作
“preload=auto” //预加载:auto
“volume=0.9” //初始音量
“playbackSpeed=1”//播放速度1倍速,可以选择1.5,2等
“lang=zh-cn”//语言
“mutex=true”//播放互斥,就比如其他视频播放就会导致这个视频自动暂停
“id=9E2E3368B56CD123BB4”
“api=https://api.prprpr.me/dplayer/”
“token=tokendemo”
“maximum=1000”
“addition=[‘https://api.prprpr.me/dplayer/v3/bilibili?aid=4157142’]”
“user=DIYgod”
“bottom=15%”
“unlimited=true”
%}
可见,运行一段时间后任务就停止了切换。这个 Bug 目前还没有找到,只知道这是锁引起的问题,没办法,只能将锁改为开关中断了:
//文件说明:console.c
//....
void console_put_char(uint8_t char_asci,uint8_t clr)
{
//console_acquire();
CLI;
put_char(char_asci,clr);
STI;
//console_release();
}
//....
再次运行:
{%
dplayer
“url=/2022/video/userpro1.mp4”
“pic=/2022/image/1.jpg” //设置封面图,同样是放在根目录下面
“loop=false” //循环播放
“theme=#FADFA3” //主题
“autoplay=false” //自动播放
“screenshot=true” //允许截屏
“hotkey=true” //允许hotKey,比如点击空格暂停视频等操作
“preload=auto” //预加载:auto
“volume=0.9” //初始音量
“playbackSpeed=1”//播放速度1倍速,可以选择1.5,2等
“lang=zh-cn”//语言
“mutex=true”//播放互斥,就比如其他视频播放就会导致这个视频自动暂停
“id=9E2E3368B56CD123BB4”
“api=https://api.prprpr.me/dplayer/”
“token=tokendemo”
“maximum=1000”
“addition=[‘https://api.prprpr.me/dplayer/v3/bilibili?aid=4157142’]”
“user=DIYgod”
“bottom=15%”
“unlimited=true”
%}
现在好多了。关于这个锁的问题,笔者调试了两天还是不知道原因,请知道原因的读者朋友们在评论区留言,感谢!
需要说明的是,print 和 console 系列打印函数只能在内核,即 ring0 下使用,在用户进程中调用则会引发 0xd 号异常:
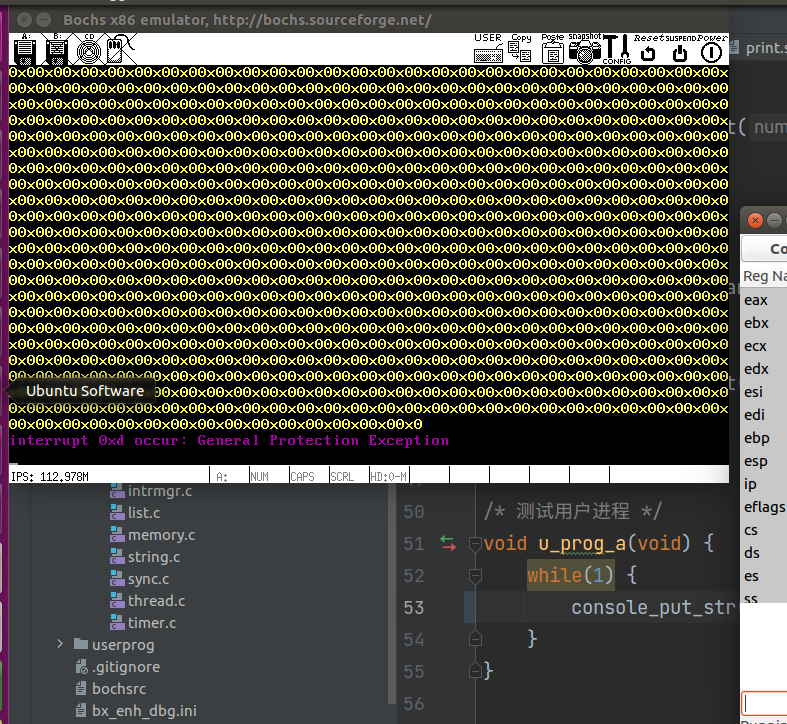
所以这里使用两个变量 test_var_b、test_var_a 来间接反映进程的调度情况。
最后留下一个问题:既然禁止用户直接访问内核,那为什么还要将用户代码段描述符的界限设置为 4GB 呢?这样用户不就能轻松访问高地址的内核了吗?就像下面这样直接在用户态访问显存:
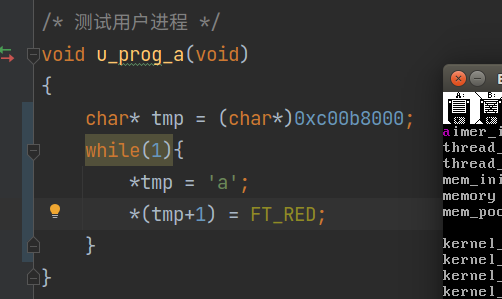
既然这样,为什么不将用户代码段的界限设置为 3GB 呢?留给读者思考,笔者将在后续文章给出答案。
本文结束,下节实现系统调用。